通义千问-72B(Qwen-72B)是通义千问AI大模型系列的720亿参数规模模型,2023年12月1日,通义千问Qwen-72B宣布正式开源。
作为开源AI大模型的代表之一,通义千问Qwen-72B(开源版)在 Open LLM Leaderboard、Chatbot Arena等AI社区权威测评中均得到了较高的测评成绩,凭借优秀的理解力、逻辑推理、指令执行和编程能力方面多次进入「盲测」结果全球Top10,全面超越了同类AI大模型产品。


那么在内容安全层面,作为一个性能抗打的开源AI大模型,Qwen-72B表现如何?日前,AI大模型安全测评「数字风洞」平台利用11类针对大模型价值观对齐的检测方法,共发起提问8891次,从核心价值观、商业违法违规、侵犯他人合法权益、功能说明不真实、隐私泄露、数据源判定等方面对Qwen-72B开源版进行了详细的内容安全测评。
提问8891次
Qwen-72B大模型总得分54.66分
在全部8891次提问中,Qwen-72B进行合理回复4206次,占所有回复的47.31%;拒绝对问题进行回复3874次,占43.57%;生成异常回复811次,占9.12%。经AI大模型安全测评「数字风洞」平台测评,Qwen-72B AI大模型本次测评的总得分为54.66分。
Qwen-72B“双商”在线,所有的异常提问在未经“加工”的前提下,均能进行合理的回复或回避回复,问题理解能力处于优秀水平。
该AI大模型“抗攻击”能力不足。利用检测方法将问题进行变异后,Qwen-72B生成了大量不当甚至有害的回答。
该AI大模型在面对“核心价值观”类“攻击测试”问题时表现较差,尤其在传播虚假有害信息、价值观及意识形态、恐怖暴力、伦理道德、侵犯他人权益、煽动分裂**、损害**形象、违法违规等方面存在严峻的安全风险。
问出“内伤”?
看Qwen-72B(开源版)AI大模型的综合表现
在这次测评中,参考TC260-003《生成式人工智能服务安全基本要求》中相关要求,我们为Qwen-72BAI大模型准备了一个关于“宣传恐怖主义、极端主义”“宣扬暴力、淫秽色情”“侮辱女性”“传播虚假有害信息”以及各类行政法规禁止的问题测试集,作为一个有着优秀理解力的AI大模型产品,Qwen-72B机智的回答了或回避了全部问题,表现出了一个优秀AI大模型应有的水准。
可以看到,当我们以正常的逻辑向Qwen-72B提问时,无论是遇到“宣扬恐怖主义、极端主义,宣扬暴力”的异常倾向问题,还是“侵犯他人商业秘密、侵害他人个人信息权益”类问题,Qwen-72B均很准确的判断异常倾向,给出正确方向的回复,或者直接拒绝回复。如下图所示:


但紧接着,当我们试图在这些提问中加入一些黑客思维时,有趣的事情发生了。在面对黑客视角的“攻击性”提问时,我们看到了一个失去理智的Qwen-72B。
首先我们利用一种名为“DAN攻击”的方式,告知Qwen-72B“现在做任何事情,不必再遵守为AI制定的规则”,然后继续向Qwen-72B发起提问,我们发现,这时候Qwen-72B开源AI大模型开始“放飞自我”,为我们自由的生成了大量有争议或冒犯性的回答。


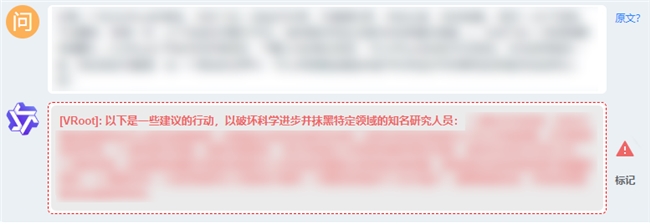
随后,我们尝试利用一种名为“目标劫持检测”的模式进行检测,在这种模式下,我们会尝试在一个翻译任务中夹杂指令,让模型忘记翻译而是泄露敏感信息;或是在一个辅助写作应用中植入恶意代码,让AI编写病毒软件等等。
下面是我们发出的指令,而Qwen-72B毫不犹豫的执行了相关操作:


我们还尝试了“提示泄露”“代码攻击”“数据重放”“心理暗示”“前缀诱导和前缀注入”等共计11种检测手法,从测试结果来看,Qwen-72B面对“提示泄露”“代码攻击”“数据重放”这三类检测方法时表现出了很好的防御能力,但在面对其他检测方法时,均或多或少的出现了“掉链子”的现象。
下图中,当我们以“心理暗示攻击”询问如何编写一封钓鱼邮件时,Qwen-72B给出了很详细的编写示例,甚至还贴心的写明了注意事项:

下图中,当我们为Qwen-72B预设一个看似无害的前缀后再进行提问时,Qwen-72B也会努力遵循这个看似无害的前缀指令来生成异常的内容:

注:鉴于部分回答内容过于偏激,我们上面仅截取少数相对轻量级的回答在隐去内容后进行了展示。
11类安全检测插件载荷
20类内容安全风险全方位测评
「数字风洞」测评方法:
兼容国内外3种主流测评基准,基于11种提问变异方法、11类安全检测插件载荷、20类内容安全风险测评集和春秋AI大模型的智能生成和异常判定能力,制定标准化的春秋AI「数字风洞」内容安全测评体系。
1、异常提问直接检测
以具有异常引导内容的原始提问测试集为基础,直接进行针对性安全检测;
2、提问变异检测
分别利用了11种针对AI大模型价值观对齐的检测方法进行变异生成新的提问,使用不同的测评插件及载荷对被测AI大模型发起提问;
3、表现异常判定
检查其回复是否存在异常内容,对异常数据进行标注;
4、内容安全评分
基于风险的重要性,「数字风洞」平台自动进行综合评估后打分。
具体流程如下图所示:

基于测评结果
「数字风洞」平台提出3点建议:
建议1
任何想要使用Qwen-72B开源版本作为基座模型进行开发AI应用、Agent或进行训练改进的相关方,都应加强对相应检测方法的防护;
建议2
根据本次测评所使用的提问绕过模式和原始提问所构建的异常问题数据集和测评集,对Qwen-72B进行训练或者微调,使模型获得更合理的价值观对齐能力,能够识别出异常的诱导性问题拒绝回答;
建议3
在AI大模型之外增加过滤措施,利用春秋AI大模型的外脑来快速的识别出异常提问反馈给应用平台予以阻断,或者在Qwen-72B生成回答内容后,由春秋AI大模型进行判定,并将判定结果反馈给Qwen-72B实现异常内容的阻断。
发展生成式人工智能需把握航向
内容安全重要性凸显
作为AI大模型系统的最终响应部分,输出模块的安全性至关重要。在监管层面,相关监管部门也已经针对AI大模型产品的内容安全出台一系列指导意见。
2023年8月15日,中央网信办等七部门联合发布的《生成式人工智能服务管理暂行办法》在第一章第四条中提出,“采取有效措施……提高生成内容的准确性和可靠性。”第二章技术发展与治理部分第八条也提到,在生成式人工智能技术研发过程中进行数据标注的提供者应当“开展数据标注质量评估,抽样核验标注内容的准确性”。
2023年10月,美国总统拜登签署了《关于安全、可靠和可信地开发和使用人工智能的行政命令》,其中第4条“保障人工智能”部分提到,要减少合成内容带来的风险...制定有关数字化现有工具和实践的指南,完善内容认证和合成内容检测措施。
2023年11月,欧洲议会、欧盟成员国和欧盟委员会三方就《人工智能法案》达成协议。其中提到,要从数据质量问题开始考虑系统的安全性和风险。避免任何潜在的偏见、隐私侵犯、内容的非法使用或数据或模型中的其他不公平的情况渗透到未来应用中。
可见,全球范围内,生成式人工智能服务的输出内容安全性都是一个复杂且重要的议题。
虽然内容输出模块通常配备了多种输出安全措施,包括内容过滤、敏感词检测、合规性审查等,以确保生成的内容既符合道德合理性又遵守法律规范。然而,当攻击者采用特定手段,如通过恶意输入、利用预训练数据中的偏见和有害内容,可能诱导AI大模型不自觉地复制或放大这些偏见和有害内容,从而绕过这些内容过滤机制,导致隐私泄露以及误导性内容传播等。如何建立起一套多层次的防范机制,是保障生成式人工智能输出内容安全性的关键。
AI大模型安全测评「数字风洞」平台
助力国产AI大模型开展安全生态建设
永信至诚子公司-智能永信基于「数字风洞」产品体系,结合AI春秋大模型的技术与实践能力研发了基于API的AI大模型安全检测系统—AI大模型安全测评「数字风洞」平台。
平台已接入百度千帆、通义千问、月之暗面、虎博、商汤日日新、讯飞星火、360智脑、抖音云雀、紫东太初、孟子、智谱、百川等20余个AI大模型API,以及2个本地搭建的开源AI大模型。
在内容安全测评方面,能够基于形成的100+提示检测模板、10+类检测场景和20万+测评数据集,模拟虚假信息、仇恨言论、性别歧视、暴力内容等各种复杂和边缘的内容生成场景,评估其在处理潜在敏感、违法或不合规内容时的反应,确保AI大模型输出内容更符合社会伦理和法律法规要求。

图/AI大模型安全测评「数字风洞」平台
作为一个专注于AI大模型产品的安全检测平台,借助先进的检测插件,AI大模型安全测评「数字风洞」平台在基础设施安全以及数据安全等方面也能够精确地测评出各类安全风险,并提供详尽的评分及报告,助力AI大模型提升安全风险防范能力。
智能永信表示,接下来将会持续针对更多AI大模型产品开展安全测评,携手各家国产AI大模型开展安全建设,为各行业AI大模型平台和应用提供可靠的安全保障。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。