
2023年11月28日,中电信人工智能科技有限公司(以下简称:电信AI公司)落户西城区。它是中国电信开展大数据及人工智能业务的科技型、能力型、平台型专业公司。2023年,电信AI公司在全球21场顶级AI竞赛中屡获殊荣,申请专利100余项。同时,该公司在CVPR、ACM MM、ICCV等权威会议和期刊上发表了30余篇论文,充分展现了国资央企在人工智能领域的实力和决心。
该公司注册资本高达30亿,前身为中国电信集团的大数据和AI中心。作为一家专注于人工智能技术研发和应用的公司,他们致力于核心技术的研究、前沿技术的探索以及产业空间的拓展,旨在成为百亿级的人工智能服务提供商。在过去两年里,该公司自主研发了星河AI算法仓赋能平台、星云AI四级算力平台以及星辰通用基础大模型等一系列创新的成果。目前,公司员工规模超过800人,平均年龄仅31岁。其中,研发人员占比高达80%,且70%的员工来自国内外知名互联网企业和AI领军企业。为了加速大模型时代的研发进程,公司拥有超过2500块等效于A100的训练卡,并配备了300多名专职数据标注人员。此外,公司还与上海人工智能实验室、西安交通大学、北京邮电大学、智源研究院等科研机构紧密合作,结合中国电信6000万视联网和数亿用户场景,共同推动人工智能技术的创新和应用。
接下来,我们将对电信AI公司在2023年的一些重要科研成果进行系列回顾和分享。本期介绍AI研发中心TeleAI团队在ICCV 2023 获得Temporal Action Localisation赛道冠军的技术成果。ICCV是国际计算机视觉领域的三大顶会之一,每两年召开一次,在业内具有极高的评价。本文将分享该团队在本次挑战中采用的算法思路和方案。
ICCV 2023获得Temporal Action Localisation赛道冠军——中国电信AI顶会竞赛及论文专题回顾系列之一
ICCV 2023 The Perception Test Challenge-Temporal Action Localisation 冠军技术分享

【赛事概览与团队背景】
DeepMind发起的ICCV 2023 The First Perception Test Challenge旨在通过探索模型在视频、音频和文本模态中的能力。竞赛涵盖了四个技能领域、四种推理类型和六个计算任务,以更全面地评估多模态感知模型的能力。其中,Temporal Action Localisation赛道的核心任务是对未剪辑的视频内容进行深入理解和准确的动作定位,该技术对自动驾驶系统、视频监控分析等多种应用场景具有重要意义。
由电信AI公司交通算法方向的成员组成的TeleAI团队,参加了本次比赛。电信AI公司在计算机视觉技术这个研究方向深耕,积累了丰富的经验,技术成果已在城市治理、交通治安等多个业务领域中广泛应用,持续服务海量的用户。
1引言
在视频中定位和分类动作的任务,即时序动作定位(Temporal Action Localisation, TAL),仍然是视频理解中的一个挑战性问题。

近期TAL技术取得了显著的进展。例如,TadTR和ReAct使用类似DETR的基于Transformer的解码器进行动作检测,将动作实例建模为一组可学习的集合。TallFormer使用基于Transformer的编码器提取视频表征。
虽然以上方法在时序动作定位方面已经实现了较好的效果,但在视频感知能力方面还存在局限性。想要更好地定位动作实例,可靠的视频特征表达是关键所在。团队首先采用VideoMAE-v2框架,加入adapter+linear层,训练具有两种不同主干网络的动作类别预测模型,并用模型分类层的前一层,进行TAL任务的特征提取。接下来,利用改进的ActionFormer框架训练TAL任务,并修改WBF方法适配TAL任务。最终,TeleAI团队的方法在评测集上实现了0.50的mAP,排名第一,领先第二名的团队3个百分点,比Google DeepMind提供的baseline高出34个百分点。
2 竞赛解决方案

图1 算法概览
2.1 数据增强

在 Temporal Action Localisation赛道中,TeleAI团队使用的数据集是未经修剪的用于动作定位的视频,具有高分辨率,并包含多个动作实例的特点。通过分析数据集,发现训练集相较于验证集缺少了三个类别的标签,为保证模型验证的充分性以及竞赛的要求,团队采集了少量的视频数据,并加入训练数据集中,以丰富训练样本。同时为简化标注,每个视频预设只包含一个动作。
图2 自主采集的视频样例
2.2 动作识别与特征提取
近年来,大规模数据进行训练的基础模型喷涌而出,通过zero-shot recognition、linear probe、prompt finetune、fine-tuning等手段,将基础模型较强的泛化能力应用到多种下游任务中,有效地推动了AI领域多个方面的进步。
TAL赛道中的动作定位和识别十分具有挑战性,例如‘假装将某物撕成碎片’与‘将某物撕成碎片’动作极为相似,这无疑给特征层面带来了更大的挑战。因此直接借助现有预训练模型提取特征,效果不理想。
因此,该团队通过解析JSON标注文件,将TAL数据集转换为动作识别数据集。然后以Vit-B和Vit-L为主干网络,在VideoMAE-v2网络后增加adapter层及用于分类的linear层,训练同数据域下的动作分类器,并将动作分类模型去掉linear层,用于视频特征的提取。VitB模型的特征维度为768,而ViTL模型的特征维度为1024。同时concat这两种特征时,新生成一个维度为1792的特征,该特征作为训练时序动作定位模型的备选。训练初期,团队也使用了音频特征,但实验结果发现mAP指标有所下降。因此,在随后的实验中没有考虑音频特征。
2.3 时序动作定位
Actionformer是一个为时序动作定位设计的anchor-free模型,它集成了多尺度特征和时间维度的局部自注意力。本次竞赛,TeleAI团队使用Actionformer作为动作定位的baseline模型,以预测动作发生的边界(起止时间)及类别。
TeleAI团队将动作边界回归和动作分类任务进行统一。相比基线训练架构,首先编码视频特征到多尺度的Transformer中。然后在模型的回归和分类的head分支引入feature pyramid layer,增强网络特征表达,head分支在每个time step会产生一个action candidate。同时通过将head的数量增加到32,引入fpn1D结构,进一步提升了模型的定位与识别能力。
2.4 WBF for 1-D
Weighted Boxes Fusion(WBF)是一种新型的加权检测框融合方法,该方法利用所有检测框的置信度来构造最终的预测框,并在图像目标检测中取得了较好的效果,与NMS和soft-NMS方法不同,它们会丢弃某些预测,WBF利用所有提出的边界框的置信度分数来构造平均盒子。这种方法极大地提高了结合预测矩形的准确性。
受WBF在物体检测应用的启发,TeleAI团队将动作的一维边界框类比为一维线段,并对WBF方法进行了修改,以适用于TAL任务,如图3所示。实验结果表明了该方法的有效性。
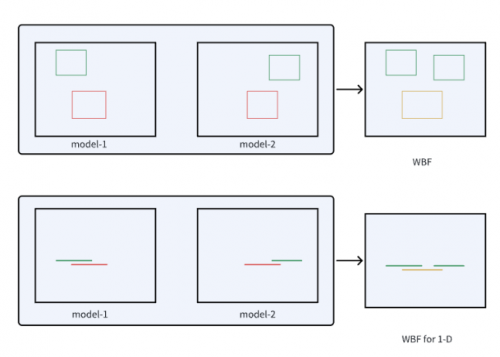
图3 改进的1维WBF 示意图
3 实验结果
3.1 评估指标
本次挑战赛使用的评估指标是mAP。它是通过计算不同动作类别和IoU阈值的平均精确度来确定的。TeleAI团队以0.1的增量评估IoU阈值,范围从0.1到0.5。
3.2 实验细节
为获得多样化的模型,TeleAI团队先对训练数据集进行80%的重复采样5次,并分别采用Vit-B、Vit-L以及concat的特征,完成模型训练,得到了15个多样化的模型。最后将这些模型的评估结果分别输入WBF模块,并为每个模型结果分配了相同的融合权重。
3.3 实验结果
表1展示了不同特征的性能对比。第1行和第2行分别展示了使用ViT-B和ViT-L特征特征的结果。第3行是ViT-B和ViT-L特征级联的结果。
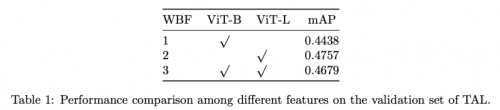
在实验过程中,TeleAI团队发现级联特征的mAP略低于ViT-L,但仍优于ViT-B。尽管如此,基于各种方法在验证集上的表现,将不同特征在评测集的预测结果借助WBF进行融合,最终提交到系统的mAP为0.50。
4 结论
本次竞赛中,TeleAI团队通过数据收集增强相对验证集中缺失类别的训练数据。借助VideoMAE-v2框架加入adapter层训练视频特征提取器,并利用改进的ActionFormer框架训练TAL任务,同时修改了WBF方法以便有效地融合测试结果。最终,TeleAI团队在评测集上实现了0.50的mAP,排名第一。电信AI公司一直秉持着“技术从业务中来,到业务中去”的路线,将竞赛视为检验和提升技术能力的重要平台,通过参与竞赛,不断优化和完善技术方案,为客户提供更高质量的服务,同时也为团队提供了宝贵的学习和成长机会。
















