腾讯AI Lab 三篇AIGC学术研究成果入选国际顶级学术会议SIGGRAPH2024,在3D自由编辑、3D物体重建、实时角色控制方面展示出领先的研究实力。其中采用3D-Gaussian Splatting的TIP-Editor技术在基于文本、图像提示和边界框的3D自由编辑上展现了强大的能力,在多项主客观对比指标上都超越了业界有名的Instruct-N2N和DreamEditor;基于Ripmap编码的神经辐射场技术(Rip-NeRF)实现了从多视角图片进行3D物体重建,以及从不同距离,不同分辨率进行反走样地渲染,在渲染图像质量方面达到了SOTA;基于Diffusion Transformer的条件自回归动作扩散模型(Conditional Autoregressive Motion Diffusion Model - CAMDM)在3D游戏角色的动作控制上突破了过去技术的瓶颈,首次达到视觉质量高、自然随机多样性强,以及可同时支持多风格角色并在风格多样的人物动作间自然切换等多个条件的最优。这些成果体现出了在3D虚拟人、游戏场景制作、视频生成等领域广阔的应用前景。
SIGGRAPH(ACM Special Interest Group on Computer Graphics and Interactive Techniques)具有深远的历史和影响力,一直是全世界计算机图形和交互技术领域的焦点,历年大会都有丰富的成果展示,比如现在很流行的像素、图层、顶点等概念,最初大都是在SIGGRAPH上发表的学术报告。
研究一:TIP-Editor:基于文本+图片提示词的3D-GS场景编辑

中山大学 HCP 实验室联合腾讯AI Lab实验室共同发表论文《TIP-Editor: An Accurate 3D Editor Following Both Text-Prompts And Image-Prompts》,该论文已被 SIGGRAPH 2024接收,同时收录于图形学顶级期刊 ACM Transactions on Graphics。

论文提出了一个名为TIP-Editor的3D场景编辑框架,它可以接受文本、图像提示和3D边界框来指定编辑区域。通过图像提示,用户可以方便地补充文本描述,从而准确控制目标内容的详细外观/风格。具体而言,TIP-Editor采用了逐步个性化的2D策略来更好地学习现有场景和参考图像的表示,其中提出了局部化损失以鼓励根据边界框指定的正确对象放置。
此外,TIP-Editor使用显式且灵活的3D高斯[1]作为3D表示,以便在保持背景不变的同时进行局部编辑。大量实验证明,TIP-Editor能够在指定的边界框区域内根据文本和图像提示进行准确的编辑,从质量和定量上一致优于基准方法。
方法上,本研究选择三维Gaussian Splatting(GS)来表示三维场景,因为GS是一种显式且高度灵活的三维表示方法,对于以下编辑操作尤其有利,特别是局部编辑。
具体体现在,Splatting 可以将三维空间中的点投影到二维图像平面上,这些投影的数据点以某种方式在图像上产生视觉效果,从而呈现在最终的渲染图像中。
优点:①渲染效果十分真实。②渲染速度快。③点云是显式表达,并且灵活,更适合进行局部编辑和编辑前后有明显形状差异的情形。
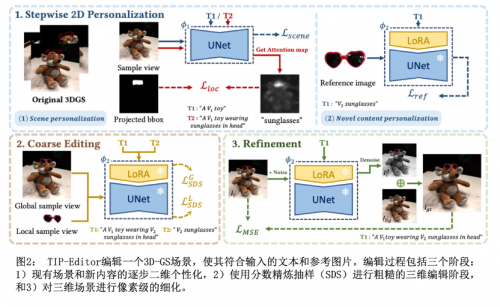
算法上,在现有场景的2D个性化中[2,3],研究员们提出了一种基于注意力的定位损失,以强迫已有内容和参考图像中提供的3D边界框指定的新内容之间的交互作用(参考图像在此步骤中不参与)。其次,在新内容的2D个性化中,引入了LoRA[3]层,以更好地捕捉参考图像中指定物品的独特特征。
随后,采用 DreamFusion提出的 SDS[4] 损失来利用第一步微调好的扩散模型对3D-GS场景中的编辑区域(3D box中的区域)进行优化,使场景符合文本和参考图的描述。通过将随机渲染的视角和文本提示输入扩散模型,我们计算 SDS 损失并将梯度反向传播到3D-GS中,更新模型参数。
最后,考虑到直接使用SDS损失优化的3D结果通常会包含一些伪影,作者还引入了像素级重建损失以有效增强编辑结果的质量。
实验结果:

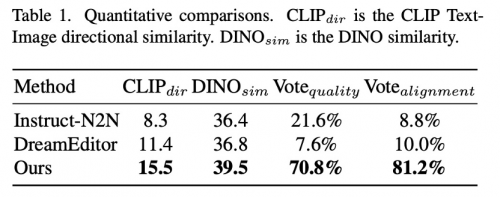
在实验中,我们引入两个文本驱动的3D场景编辑方法Instruct-N2N[5]和DreamEditor[6]进行对比。结果明显表明本方法在两个度量指标上都优于其他方法,这表明生成的外观更好地与文本提示和图像提示相吻合。用户研究也得出了类似的结论。本研究的结果在“质量”评估(70.8%票数)和“对齐”评估(81.2%票数)方面都大幅超过了基线方法。
据了解,该项技术在3D生成以及影视、视频等创作领域都有广阔的应用前景,可实现对已有人物、物体(环绕拍摄建模之后)或者3D模型进行二创(编辑),360度展示二创(编辑)过后的物体的效果,方便把创作者的想法具象化。
参考文献:
[1]Kerbl B, Kopanas G, Leimkühler T, et al. 3D gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics 2023
[2]Hu E J, Shen Y, Wallis P, et al. LoRA: Low-rank adaptation of large language models. International Conference on Learning Representations (ICLR) 2022
[3]Ruiz N, Li Y, Jampani V, et al. DreamBooth: Fine tuning text-to-image diffusion models for subject-driven generation. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2023
[4]Poole B, Jain A, Barron J T, et al. DreamFusion: Text-to-3D using 2D diffusion. International Conference on Learning Representations (ICLR) 2023
[5]Haque A, Tancik M, Efros A A, et al. Instruct-NeRF2NeRF: Editing 3D scenes with instructions. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) 2023
[6]Zhuang J, Wang C, Lin L, et al. DreamEditor: Text-driven 3D scene editing with neural fields. SIGGRAPH Asia 2023 Conference Papers
研究二:Rip-NeRF: Anti-aliasing Radiance Fields with Ripmap-Encoded Platonic Solids
中文名称:Rip-NeRF: 基于Ripmap编码柏拉图多面体的反走样神经辐射场
Paper:[2405.02386] Rip-NeRF: Anti-aliasing Radiance Fields with Ripmap-Encoded Platonic Solids
Project page:Rip-NeRF: Anti-aliasing Radiance Fields with Ripmap-Encoded Platonic Solids

本研究工作由腾讯AI Lab联合来自清华大学,北航,以及北理工的教授、本科生等共同完成,被国际计算机图形学旗舰会议ACM SIGGRAPH 2024接收,所属的子领域为Modeling and Rendering。

论文提出了一种物体高质量重建方法,Rip-NeRF,实现了从输入的多视角图片中恢复出高保真的3D神经辐射场,进而可以从任意视角渲染出具有真实感的照片。Rip-NeRF相比于之前方法在不同相机距离,以及不同分辨率渲染时可以避免走样的瑕疵,并且渲染出更多细节的照片。此外该方法的重建速度和模型紧凑度方面也得到了一定的提升。
神经辐射场 (NeRF) [1] 在高真实感重建和渲染方面已经取得了巨大的成就,但是其在变化的相机距离/分辨率渲染时仍然受到走样的困扰。该问题的根本原因在于我们缺少一种高效进行各向异性区域采样的方法。Mip-NeRF [2] 最早提出反走样神经辐射场的研究,但是受限于纯隐式的表征导致重建速度很慢,且质量也不尽如人意。Tri-MipRF [3] 和 Zip-NeRF [4] 基于混合表征分别采用area-sampling和multi-sampling策略实现了重建速度和质量的显著提升。但是multi-sampling策略在刻画一个区域时需要多次采样,不够高效,而Tri-MipRF的area- sampling不支持对各向异性的区域采样。
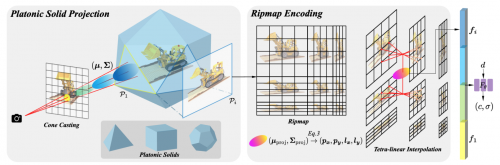
本论文提出了将3D空间投影到柏拉图多面体的非平行面上,每个面使用Ripmap进行编码,从而实现了对任意形状区域的area-sampling。其中Ripmap encoding和柏拉图多面体投影分别从2D空间上和3D到2D的映射层面支持了各向异性的区域采样。这两项技术结合起来达到了高效,精确的各向异性区域采样,从而实现了高质量,高效率的反走样。
实验结果:
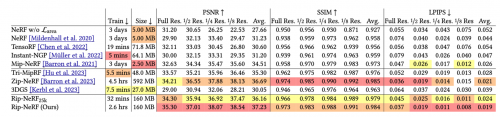

我们在多尺度Blender数据集上评测了我们的方法,定量和定性的结果都表明我们方法达到了反走样神经辐射场领域新的SOTA。并且我们方法在重建时间,模型大小方面相比于Zip-NeRF [4] 也存在优势。
从应用角度来说,该技术提供了一种现实世界数字化的强大工具,有希望应用于高真实感游戏资产的制作,从而提升玩家在游戏中的沉浸感。同时也有潜力作为一种UGC制作工具,满足玩家的个性化需求。
参考文献:
[1] Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ra- mamoorthi, and Ren Ng. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In ECCV 2020.
[2] Jonathan T. Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo MartinBrualla, and Pratul P Srinivasan. Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. In ICCV 2021.
[3] Wenbo Hu, Yuling Wang, Lin Ma, Bangbang Yang, Lin Gao, Xiao Liu, and Yuewen Ma. Tri-MipRF: Tri-Mip Representation for Efficient Anti-Aliasing Neural Radiance Fields. In ICCV 2023.
[4] Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. Zip-NeRF: Anti-Aliased Grid-Based Neural Radiance Fields. In ICCV 2023.
研究三:Taming Diffusion Probabilistic Models for Character Control
中文名称:基于扩散模型的实时角色控制

本项工作由腾讯AI Lab联合来自香港科技大学以及香港大学的教授、博士生共同完成,被国际计算机图形学旗舰会议ACM SIGGRAPH 2024接收,所属的子领域为Character Animation。本项工作的Demo视频也入选了SIGGRAPH 2024官方Technical Papers Video Trailer。
论文主要解决的是游戏、虚拟世界中动画角色的可控动作生成难题,仅需单个统一的模型,即可支持各种各样的可控NPC动作生成。
过去在游戏或者虚拟空间中,当玩家操纵手柄按键,仅提供高度抽象的控制信号输入(如拨动摇杆仅表面在空间内移动的方向,但并不描述各身体关节的具体空间运动轨迹;按下特定的按键触发想要的步态风格,同样也不描述各关节轨迹),我们需要设计算法,根据这些高度抽象的玩家控制输入,生成自然写实且符合玩家控制的人体动作。
算法的输入仅是上述高度抽象的控制信号,同时又需要对输出的生产动作有多方面的要求:
视觉质量高,如不抖动不滑步等,需流畅自然;
具有人类应有的随机动作多样性,如“醉酒”步态风格中,人物走动时应该是随机一步一个不同的踉跄,而不是单纯机械性地重复一个相同的动作;
风格多样性,人物的步态风格可以自然地在不同风格之间切换表演(如“醉酒”,“壮汉”,“小孩儿”等),不局限于单一步态风格;
轨迹可控性,除风格多样可控外,还需要生成的动作匹配玩家的摇杆操作,遵循玩家的控制进行空间移动;
实时性,玩家用户的操控瞬息万变,算法得具有足够快的响应,达到高帧率实时(>60fps)的响应,才能提供给玩家酣畅淋漓的操控体验。
以上这些要求,无论是学术界[1,2,3,4,5]还是工业界[6]提出的解决方案中,都无法全部满足。本研究提出的方法,是第一个可以同时满足上述要求的解决方案,特别是2)3)两点的要求,先前的方法都无法在一个统一易用的框架内达到。
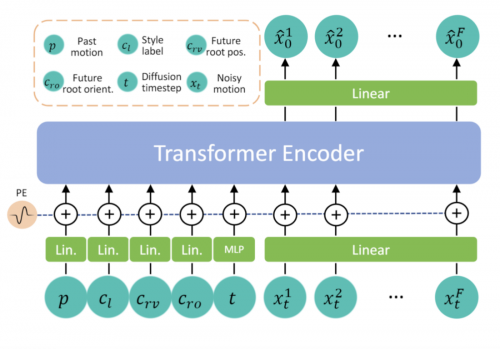
图1:Transformer-based Conditional Autoregressive Motion Diffusion Model (CAMDM)的神经网络模型架构图
论文提出了Transformer-based Conditional Autoregressive Motion Diffusion Model (CAMDM)这一模型,创新性地在实时角色控制这个任务中使用了扩散生成模型(diffusion model),来学习人类自然动捕数据中的真实数据分布,从而可以生成视觉质量高,自然随机,且风格多样的人物动作。
并且进一步地,为了实现持续性、长时间的可控生成,提出了Conditional Autoregressive Motion Diffusion Model,支持游戏引擎中,直接接受用户输入的控制条件,无限地自回归生成人物的下一时刻动作(此处,极大区别于其他工作,一次只生成几秒的动作,无法进行更加长程且流畅的动作生成)。
为了更好的学习区分各种用户控制条件(具体如,行进方向控制,人物朝向控制,以及步态风格控制),研究者采用Transformer网络架构,将各个控制信号单独地学习映射成单独的token,然后利用transformer内部的attention机制来进行生成模型的学习,避免了各种控制信号在网络内部学习时造成混淆(已有的基于深度学习的方法中极易出现此现象),大大提升了各个控制信号的有效性,即最终可控性大大提升。
为了满足实时性的要求,本项研究还提出了少步数的扩散生成模型,仅需2到8步循环去噪,无需几百上千步,即可很好地生成满足上述要求的可控人物动画。
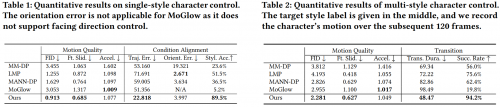
文章中的实验结果表明,CAMDM在多个关于动作质量、多样性以及可控性方面的指标优于其他已有的方法[2,3,4,5]。视频结果【待插入】也明显地验证了文章所提方法在实时多风格角色动画控制上,相较于已有方法,具有明显的优势。
这项技术在XR和高品质游戏制作中具有巨大的潜力和广阔的应用前景,它能实时控制和驱动各种各样的非玩家角色(NPC)群体,为玩家用户创造出一个更加逼真和沉浸式的虚拟世界,创造高度逼真的动态环境,使得游戏体验更加丰富精彩。例如,由AI算法驱动的虚拟人角色将很快会在高品质第一人称射击游戏等体验感较强的场景中应用,以增强玩家互动体验。
这些技术的应用前景非常广阔,无论是在游戏制作,还是广泛的XR领域,甚至是未来的工业生产、数字孪生等,都将有可能带来革命性的改变。
参考文献:
[1] Daniel Holden, Taku Komura, and Jun Saito. 2017. Phase-functioned neural networks for character control. ACM Transactions on Graphics (SIGGRAPH) 36, 4 (2017), 1–13.
[2] Sebastian Starke, Yiwei Zhao, Taku Komura, and Kazi Zaman. 2020. Local motion phases for learning multi-contact character movements. ACM Transactions on Graphics (SIGGRAPH) 39, 4 (2020), 54–1.
[3] Sebastian Starke, Ian Mason, and Taku Komura. 2022. Deepphase: Periodic autoencoders for learning motion phase manifolds. ACM Transactions on Graphics (SIGGRAPH) 41, 4 (2022), 1–13.
[4] He Zhang, Sebastian Starke, Taku Komura, and Jun Saito. 2018. Mode-adaptive neural networks for quadruped motion control. ACM Transactions on Graphics (SIGGRAPH) 37, 4 (2018), 1–11.
[5] Gustav Eje Henter, Simon Alexanderson, and Jonas Beskow. 2020. Moglow: Probabilistic and controllable motion synthesis using normalising flows. ACM Transactions on Graphics (TOG) 39, 6 (2020), 1–14.
[6] Michael Büttner and Simon Clavet. 2015. Motion Matching - The Road to Next Gen Animation.