01 选型背景
我公司致力于储能业务的开发,包括对庞大而复杂的储能装置进行设计、制造和管理。
在生产安全的重任下,我们需要实时监测电池的每一次充放电过程、电流、电压等值,以保障电池安全,而每一个变化的数据就是一个带有时间戳的时序数据。
大型储能装置十分复杂,伴随着业务的扩展,我们的设备和测点数量不断激增,数据采集的频率也在不断提高。
面对海量的时序数据,传统的处理方案显得力不从心,成本高昂且效率低下。因此,我们需要一款高性能的时序数据库,实现数据的高效处理和实时分析。
经过深入的调研之后,我们在 InfluxDB 和 IoTDB 之间选择了 IoTDB 作为储能业务线的时序数据库。
IoTDB 1.0 版本后支持了分布式部署,其数据分区存储的高可扩展性,以及多副本存储实现了无单点故障的高可用性,都深深吸引了我们。
而且,IoTDB 搭配了多种一致性协议,能够适配不同的场景,这种易于横向扩展的系统架构,完美匹配了我们业务的发展趋势。
02 部署架构
考虑到将 IoTDB 部署在物理服务器上,通过公网进行业务应用交互可能会带来数据延迟和运维成本问题,并且需要从头规划计算、存储以及监控系统,整个过程耗时漫长,不利于项目推进。
最终,我们决定直接在业务应用的 K8S 环境上部署 IoTDB,实现云上集成应用。这样不仅可以提高运维的一致性,也充分利用了云环境的弹性。
部署 IoTDB 后的业务架构是这样的:在储能设备端,电池簇持续实时上报增量时序数据,并每隔 5 秒上报一次超过 10 万指标的全量时序数据。
这些数据通过站端转发服务器,使用 MQTT 协议传输至云端,经过 EMQX 的数据转换后,存储至阿里云环境中部署的 IoTDB 数据库,并进一步进行数据的查询、计算与分析。

IoTDB 新颖的分布式架构和高可用模式,为我们提供了强有力的数据存储保障,因此目前我们采用了 3C3D 的高性能分布式架构。
对于整体存储空间,IoTDB 支持使用公有云的 SSD 云盘随时扩容,DataNode 节点容量也可以通过 scale StatefulSet 工作负载进行扩容,为我们的业务架构提供了非常高的灵活性。
为满足实时监控处理需求,我们利用了 IoTDB 内置的 Prometheus Exporter,快速接入监控,实时了解集群状态,为性能优化指明方向。
在数据备份方面,我们采用了 Velero 对 IoTDB 相关负载进行备份,数据可以直接备份到 OSS 上,也可以通过 crontab 定时备份,并使用 velero hook annotation 在备份前进行强制 flush 刷盘,以保障备份过程中的数据完整性。
值得一提的是,在部署落地的过程中,IoTDB 的用户文档描述清晰,运维简便,上手成本低,大大方便了我们运维人员的部署工作。
并且,我们深深感受到 IoTDB 背后有一群热爱研发的程序员,他们的运维支持稳定可靠、响应积极快速,我们生产中遇到的问题能够在很短时间内获得很多实质性的帮助,因此我们对于 IoTDB 产品和团队是非常信任的。

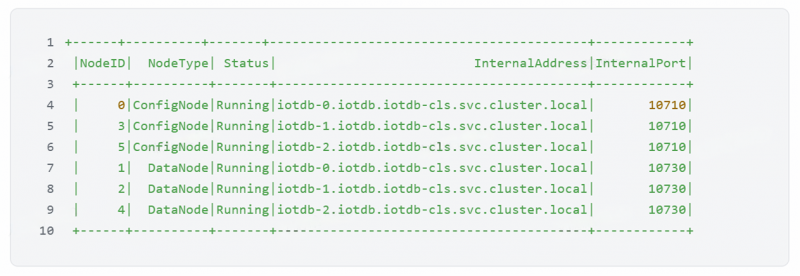
我们的 IoTDB 集群配置如下:

使用的 IoTDB 数据备份脚本如下:

03 应用效果
以下举例两个 IoTDB 在我们的储能业务中的实际应用场景:
业务场景一:在某大型储能业务中,IoTDB 共监测 150 个设备,10000 测点,1 秒采集一次上报的时序数据。其集群写入性能稳定实现千万级吞吐,并发 10 个聚合查询场景,平均耗时都在 1 秒之内,各项监控指标表现优异,完全满足我们的业务需求。
在该场景,我们使用 IoT-Benchmark 进行压测的结果如下:
集群设置:
性能表现:


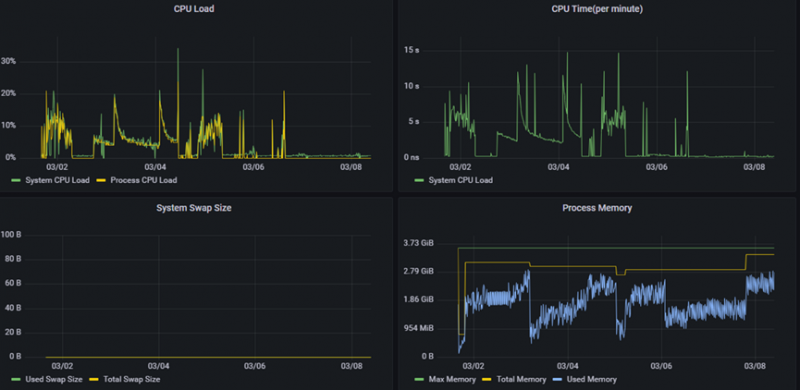
业务场景二:在某大型储能业务中,IoTDB 共监测 150 个设备,1 分钟采集一次,连续上报 3 个月的时序数据,覆盖测点数近 150 亿个。IoTDB 的千万级写入性能完全满足场景需要。在核心聚合查询场景中,SQL 结果均在 1 秒内返回,而对于如此数量的模型数据,关系型数据库是不可能完成查询的。
聚合查询场景举例如下:

04 未来展望
部署 IoTDB 后,我们不但可以很自豪地和客户说:“我们使用的是国产时序数据库。”而且这款国产时序数据库还能够真正高效地管理海量时序数据,有效提升数据的处理和实时分析能力,为公司储能业务的电池安全监控提供有力保障。
未来,我们希望抽象出一套 operator 来满足各种不同架构的 IoTDB 部署,同时实现 K8S 环境的一键部署。我们也希望与 IoTDB 团队继续保持紧密合作,适配更大规模的数据体量,通过对更多时序数据的有效管理,进一步赋能我们储能业务的发展。