作为全球机器学习三大顶会之一,ICML2025聚焦机器学习前沿领域,将于今年7月中旬在温哥华召开,目前大会接收的论文结果已经出炉。
本文将介绍腾讯混元团队获得ICML录用的六篇论文,覆盖模型训练、MoE模型架构、模型推理深度思考以及3D生等领域。
这些成果代表了混元团队当前关注的核心方向,也是研究员们不断探索技术前沿的努力。
1、Scaling Laws for Floating Point Quantization Training
(浮点量化训练的 Scaling Law)
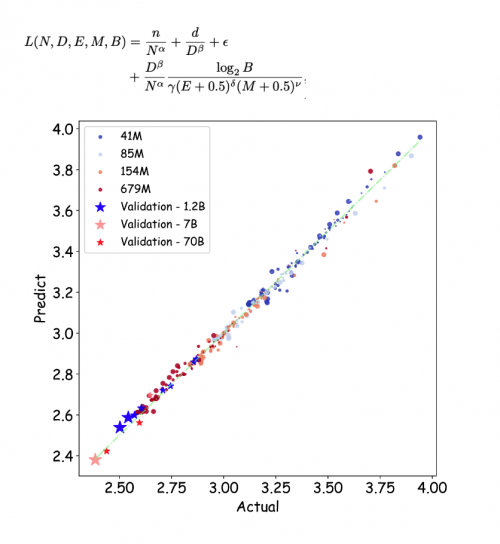
在近年来人工智能技术迅猛发展的背景下,大模型的量化训练成为业界关注的热点。量化训练,尤其是低比特浮点数训练,寻求在降低模型计算和存储成本的同时,尽可能保持其性能。腾讯混元团队的最新研究《Scaling Laws for Floating-Point Quantization Training》对这一领域进行了深入探讨,为大模型的优化和实际应用提供了理论依据。
大模型(Large Language Model, LLM)的参数规模日益庞大,这导致了训练和推理的成本显著增加。因此,降低模型精度以减少资源消耗成为了研究的重要方向。以往的研究表明,相比于整数量化,浮点数数量化在保持模型效果上表现更佳。腾讯混元团队通过366组不同参数规模和精度的浮点数量化训练实验,提出了一套浮点数量化的Scaling Laws,这为模型训练提供了重要的理论指导。
浮点数的量化结构复杂,由符号位、指数位和尾数位决定。研究团队发现,特定的指数位(E)与尾数位(M)配置关系直接影响模型的训练效果。他们推导出,在任意配置下,都存在一个模型的极限性能与数据量的关系,“超过这个临界点(Dcrit)后,继续增加数据反而会对模型效果产生负面影响”。这一发现对理解大模型在实际训练中的行为模式具有重要意义。
此外,研究还揭示,当计算资源有限时,理论上最佳的浮点数量化训练精度落在4-8比特之间。这一发现与业界在超低精度量化训练中采取的措施相符,为进一步的研究和实践提供了可行的指导方案。重要的是,这项研究表明,小模型在面对较低精度时,需要较大的数据量才能达到有效训练的效果,这一规律也为研究团队在实际开发中提供了预见,有效促进了模型性能的提升。
2、 Autonomy-of-Experts Models
(自主专家模型)
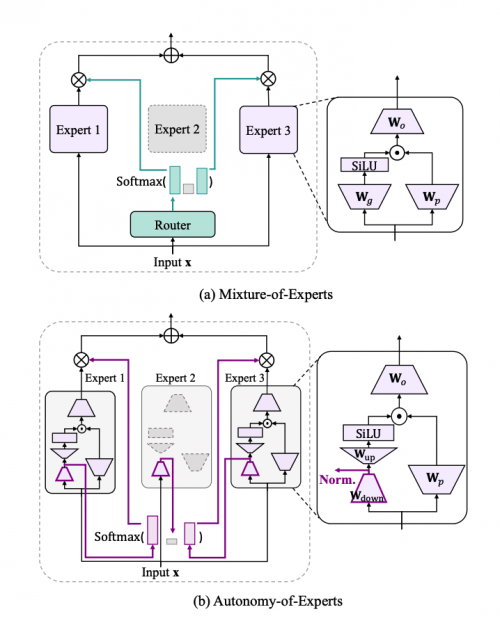
近年来,Mixture-of-Experts(MoE)模型因其提升大语言模型参数利用率与计算效率的能力,受到学术界与工业界广泛关注。然而,现有MoE普遍依赖外部路由器选择专家,这种“决策与执行分离”的架构存在关键问题:路由器无法感知专家真实能力,导致专家选择缺乏有效监督,易引发训练损失上升或专家能力漂移,训练效率低下。
为解决这一问题,我们提出 Autonomy-of-Experts(AoE) 框架,使专家具备“自我认知、自我选择”能力,从而去除显式路由器。AoE的核心思想是:专家对输入的激活强度可视为其处理信心。
研究者发现在预训练好的MoE模型(如 Mixtral 8×7B 和 Phi-3.5-MoE-instruct)中移除路由器,让所有专家对每个token并行执行前半计算,并在“暂停节点”处提取激活L2范数,用于Top-K专家筛选。尽管不更新参数,这一基于激活强度的选择策略可以极大地保持原始模型性能。这说明专家对自身能力有认知且认知可以体现在激活程度上。基于这一启发,我们在AoE中显式设计激活节点作为专家筛选信号,并在预训练阶段引导专家学习以激活强度表达处理信心。
实验表明,使用 xW_g 节点的激活 L2 范数作为筛选依据,在性能与效率间实现良好权衡。此外,为减少所有专家执行完整前向计算所带来的计算和内存压力,AoE引入低秩因式分解策略,将专家投影矩阵分解为两个小矩阵(W_down · W_up),大幅降低成本。
最终,AoE在保持约97%传统MoE推理吞吐率的同时,取得更优的下游任务表现,并展现出以下优势:专家负载更均衡;选择信心更强;激活信号自适应调整,无需人工干预。
3、RBench: Graduate-level Multi-disciplinary Benchmarks for LLM & MLLM Complex Reasoning Evaluation
(RBench:面向大语言模型与多模态大语言模型复杂推理评估的硕博级交叉学科基准测试)
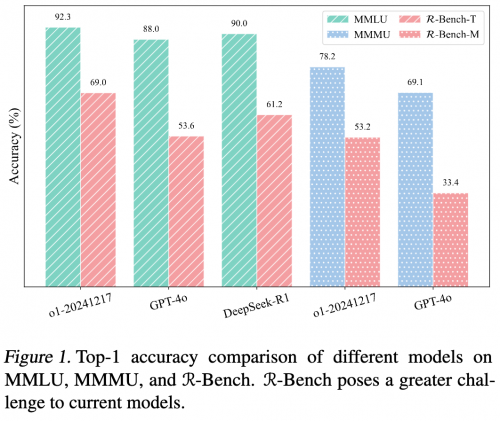
大语言模型(LLMs)在推理能力展现上不断进阶,从基础思维链提示应用迈向更智能阶段。然而,在综合考量大模型复杂推理能力时,现有评测基准存在覆盖学科有限、对多步深度推理考查不足等问题,难以全面精准衡量模型在真实复杂场景下的推理表现 。
为突破上述困境,来自清华大学、腾讯混元 、斯坦福大学等机构的研究者们,打造了多学科大模型复杂推理评测基准 RBench 。RBench 实现了:1)广泛挖掘多学科(数学、物理、化学等 19 个院系超百学科)复杂推理题目,构建高质量、多语言(含中英文)评测数据集 ;2)打造兼容语言与多模态模型评估,聚焦推理链条构建与问题解决能力考查的评测体系 。
RBench 的核心创新点涵盖:1)一套从多学科课程体系挖掘、经专业筛选优化的推理题构建流程,保障数据丰富性与质量 ;2)一个覆盖多学科、多语言,兼顾语言与多模态模型评估的综合评测基准 ;3)一组能有效区分模型复杂推理能力,助力揭示模型推理瓶颈的测试方案 。这些设计让 RBench 成为评估大模型复杂推理能力的有力工具 。
4、Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
(何必为2+3等于几绞尽脑汁?——论类O1大语言模型的过度思考问题)
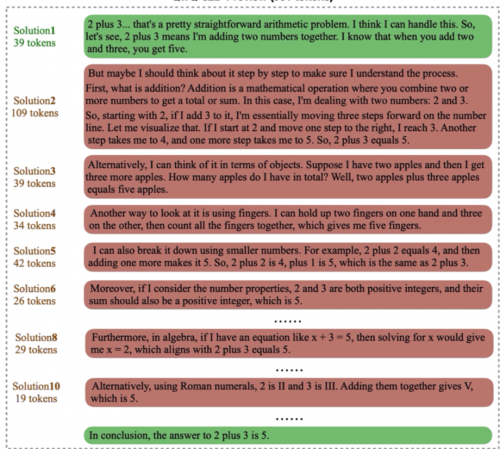
自 OpenAI 发布 o1 模型以来,它超强的逻辑推理以及难题解决能力就引发了广泛关注。在o1之后,类似的通过长思维链来提升推理性能的开源模型也纷纷面世,如 Deepseek 推出的 R1模型。这类长推理模型通过模拟人类的深度思考过程,在思维链中运用如自我反思、纠错以及探索多种解法等推理策略,展现了强大的推理时扩展(Inference-Time Scaling)性能。然而,在长推理模型成功的光环下,推理效率的问题越来越受到大家关注。
来自腾讯和上海交通大学的研究者针对长推理模型的生成效率进行了详细的研究。他们发现,长推理模型存在严重的“过度思考现象”:长推理模型在生成答案过程中,会对单一问题生成冗余的同质化解答 (solution),且后续解答对正确率贡献较低。进一步的分析发现,过度思考现象有如下三个特点:1. 冗余解答对正确率贡献较低。2. 冗余解答的策略多样性较低。3. 过度思考现象在简单问题上更严重。
为了更好地量化过度思考问题,研究者们从解答对正确率的贡献以及对推理策略多样性的贡献出发,提出了两种效率指标,分别为结果效率和过程效率,并对现有模型的表现进行了细致的分析。研究们还基于偏好优化算法提出了一个缓解过度思考的方法,通过不同方案构造精简的模型回复,并鼓励模型学习以更简单的方式回答问题。实验结果表明,提出的优化方法可以在维持数学推理性能不变的情况下,大幅度提高生成效率。
5、Critical Tokens Matter: Token-Level Contrastive Estimation Enhances LLM's Reasoning Capability
(关键词元何以重要:词元级对比估计增强大语言模型推理能力)
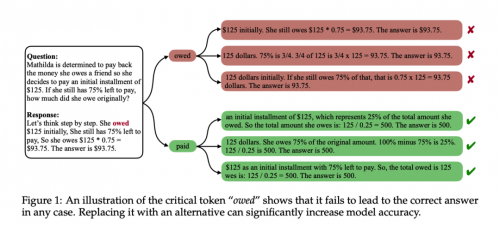
数学推理任务一直被视为衡量大语言模型(LLMs)能力的重要指标。为了提升模型在此类任务中的表现,研究者们从多方面进行了优化探索,例如通过链式思考(Chain of Thought, CoT)提示,或对错误类型进行系统分析,旨在帮助模型实现更严谨的逻辑推理和逐步推导。然而,目前对于大语言模型生成过程中最基础的单元——词元(token)层面的研究仍较为缺乏,尤其是在数学推理场景下,词元级别的影响尚未被充分揭示。
为填补这一空白,来自清华大学与腾讯的研究者在词元层面对模型推理过程进行了深入分析。他们发现并定义了一类对模型推理结果有关键影响的词元:关键词元(critical tokens)。这些关键词元并非人类通常认为的错误词元,但它们一旦出现在推理轨迹中,会显著扰乱模型的逻辑推演、破坏计算正确性,从而导致推理失败。
为进一步量化关键词元的作用,研究者提出了一套词元级别的识别与采样框架,用于定位并衡量关键词元对模型准确率的影响。在 GSM8K 和 MATH 数据集上的实验表明,仅通过简单替换错误轨迹中的关键词元,模型的推理性能即可获得显著提升,Pass@1 提高了 30%,Pass@64 提升更是高达 90%。
为了将关键词元的发现应用于大规模模型训练,研究者提出了对比估计(contrastive estimation)方法,用以高效自动化地识别关键词元。他们进一步设计了基于关键词元的 cDPO训练算法,将关键词元信息引入 DPO 训练中。实验结果显示,通过在训练阶段抑制模型对关键词元的生成倾向,cDPO 不仅能有效帮助模型区分正负示例,还显著缓解了 DPO 中存在的似然偏移问题。
6、FreeMesh: Boosting Mesh Generation with Coordinates Merging
(FreeMesh:基于坐标融合的网格生成加速框架)
在当前自回归网格生成方法体系中,下一坐标预测范式已成为实际落地的主流方案 。这类方法虽能在网格序列化建模流程中实现一定效果,但在网格标记器质量评估环节,既缺少无需训练即可从理论层面高效评估的手段,现有标记器对网格序列的压缩能力,也存在明显优化空间 。
为破解上述难题,香港科技大学、腾讯混元、华南理工大学、上海科技大学的研究者开展专项研究,提出创新方法,对网格标记器评估与序列压缩进行系统性优化。
具体研究贡献可概括为三点:
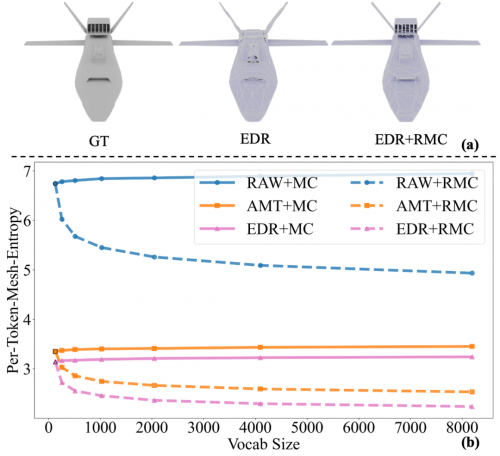
其一,构建 Per-Token-Mesh-Entropy(PTME)数学框架 ,突破传统评估对训练依赖,无需训练即可完成现有网格标记器质量评估,填补网格生成领域理论评估的空白;
其二,设计 简便有效的坐标合并技术 ,通过识别并合并高频坐标、构建新词汇表,精准压缩网格序列冗余信息,提升序列编码效率;
其三,经实验验证,将 EdgeRunner 与标记合并策略结合,实现 21.2% 的当前最优压缩比 ,充分验证方法有效性,为原生网格生成技术发展筑牢基础、注入动力 。