北京智谱华章科技有限公司的智谱CodeGeeX代码大模型参与中国信通院组织的可信AI代码大模型首轮评估,最终获得4+级评级, 成为国内首批通过该项评估的企业之一。

在信通院官方发布的评测中,给予了CodeGeeX代码大模型较高评价:
“参与本次评估的智谱CodeGeeX代码大模型在通用能力方面,其代码解释、代码生成、代码转换等方面表现突出;在专用场景方面,其支持网站开发、桌面应用开发、移动应用开发、数据库开发、人工智能开发等多个场景的能力;在应用成熟度方面,其具备较完善的数据安全合规机制,在数据分类分级、模型服务可追溯性、风险可控性及可维护性等方面均表现优秀。”
CodeGeeX代码大模型基于智谱GLM大模型通过代码数据预训练和指令微调而成,支持超过100种编程语言,具备优秀的模型特性、强大的代码能力、全面的开发辅助能力。代码补全能力支持上下文补全、跨文件补全等;研发问答能力用于代码解释、代码翻译、代码注释、代码审查、代码修复、生成单元测试等任务,显著提高开发效率。基于多来源检索增强RAG技术,可实现基于本地知识库及开源代码仓库的问答,大幅提升准确率。同时,模型具备Code Interpreter代码解释器能力,可以批量处理多种格式的文件、批量实现数据可视化、绘制数学函数图等。
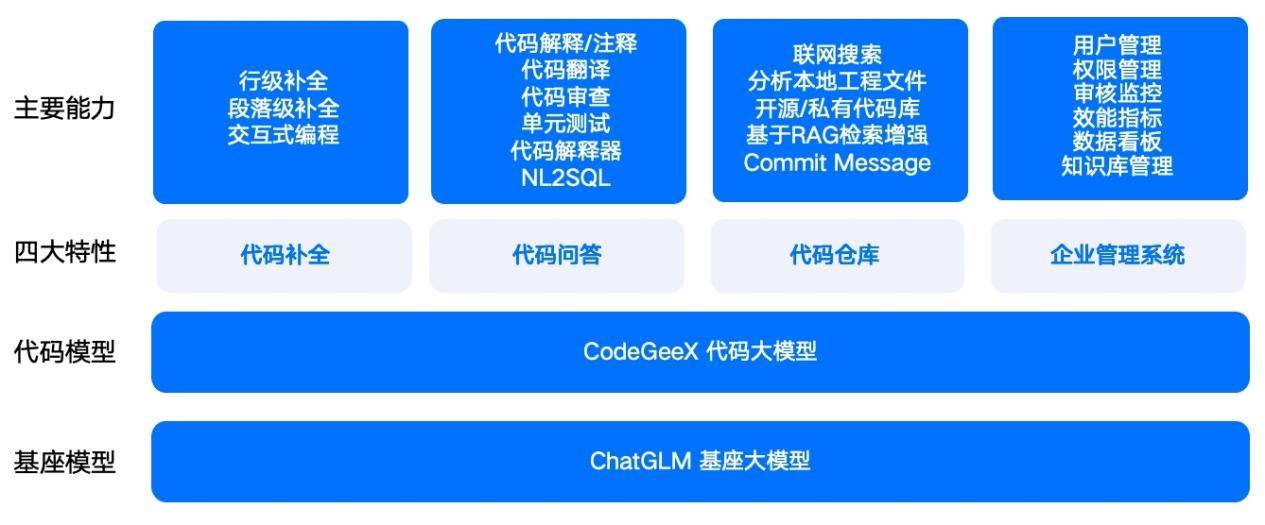
图1:CodeGeeX代码大模型的核心能力
目前,CodeGeeX插件产品的个人用户已经超过100万+,企业版本也已经广泛应用于科技、金融、医疗和制造等多个行业,每天为程序员生成超过2000万行代码,显著提高程序员的编程开发效率。CodeGeeX插件产品适配了VSCode、JetBrains IDEs全家桶、Visual Studio 2022、并独家适配了Visual Studio 2019、HBuilderX和deepin-IDE。在不同场景下,都已成为程序员必备的智能编程助手。
背景信息:信通院可信AI代码大模型评估介绍
可信AI代码大模型评估围绕通用能力、专用场景能力、应用成熟度,为模型能力提升和企业选型提供规范性参考。
(一)通用能力:考察模型的代码理解、代码生成与补全、代码转换、单测生成、代码诊断与优化、研发问答六大能力,一方面采用由多语言、多任务组成的专用评测数据集进行准确度等客观指标的评分,另一方面结合多位编码专家对可接受度指标的主观评分,综合评估代码大模型通用水平。
(二)专用场景能力:关注大模型所支持的专业场景数,如网站开发场景、数据库开发场景、大数据开发场景、人工智能开发场景等,以及相应场景下模型的代码生成和辅助编程的能力。
(三)应用成熟度:关注大模型数据管理机制、模型及其服务管理机制,评估应用实施阶段的服务质量。
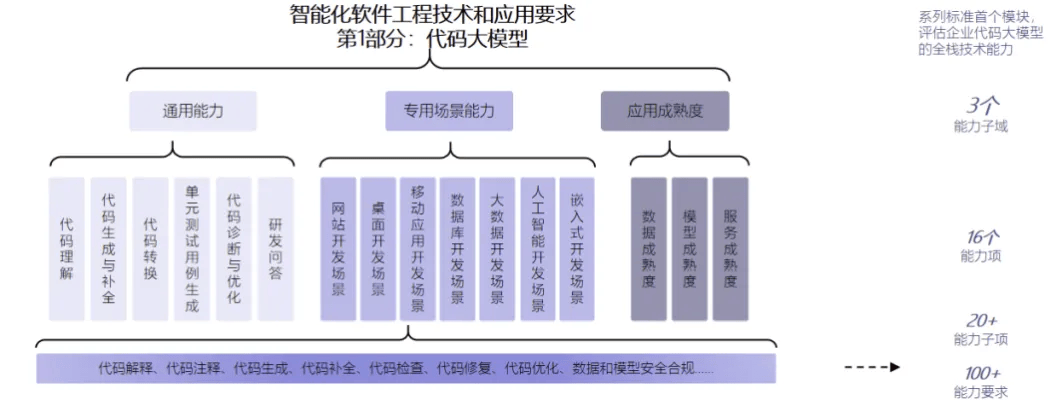
图2:可信AI代码大模型评估内容