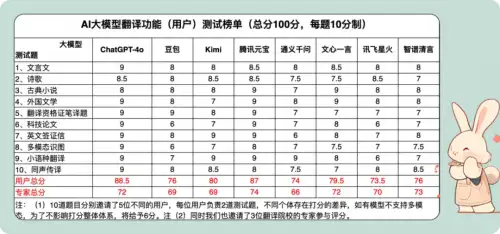
近日,一份关于八款主流AI大模型(ChatGpt-4o、豆包、kimi、腾讯元宝、通义千问、文心一言、讯飞星火和智谱清言)的翻译能力测评报告引发了科技界的广泛关注。测评通过文言文、诗词歌赋、古典小说、外国文学片段、翻译资格证真题、科技论文翻译、英文签证信、多模态识图、小语种翻译、同声传译10大测试题,对各家翻译能力进行全面考察,同时也邀请到用户以及翻译院校专家对翻译结果打分。
用户打分结果显示,ChatGPT-4o、腾讯元宝、Kimi分别以88.5分、87分、80分位列前三。专家打分结果显示,腾讯元宝、智谱清言、ChatGpt-4o/文心一言(并列)位列前三,分别是74分、73分、72分。
整体来看,基本所有大模型都具备了很成熟的翻译能力,国产大模型追平甚至在部分功能上超过了ChatGPT-4o。但是各家依然各具特色。
ChatGpt-4o在经典文本翻译、科技论文、多模态识图翻译等多个场景中均展现出较高的准确性和流畅性。文言文翻译对模型翻译挑战极大,该测试选取了对《出师表》的翻译,ChatGPT-4o 对《出师表》的翻译整体表现优秀。译文准确、流畅,基本符合专业文本的翻译要求。虽然在文学性和文言韵味的传达上有所欠缺,但整体上仍能较好地传达原文的主要信息和情感。某些细节和深层次的文化含义可能在翻译过程中略有遗失。
腾讯元宝在古典小说、外国文学、专业文献翻译领域表现出色。英译中特别是对外国经典文学的翻译,则要求模型具备强大的跨文化理解和翻译能力。在测试中,腾讯元宝对《小王子》英文原文片段进行了翻译,腾讯元宝不仅实现了语句基本通顺,符合中文表达习惯,能够正确表达原文意思,同时还保留了原小说作为儿童文学的文学风格和精炼语言特点。
在AI时代,每个人越来越需要阅读论文和各种外文资料,这些都离不开翻译。这时,专业术语和逻辑关系能否翻译得当,就很考验大模型的能力了。在对一篇3.9万个单词的科技论文翻译的过程中,这8个大模型,只有腾讯元宝和GPT-4o在给到统一的提示词后,能够直接全文翻译,并保持原文的格式。
由此可见,基本上大模型都具备了成熟的翻译能力,并在此之上每款模型都有其独特的优势和适用场景。基于本测评,用户也可根据自身需要和实际场景来选择AI翻译工具,做到实时、高效、全方位的跨语言交流。(来源:聊城新闻网)
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。