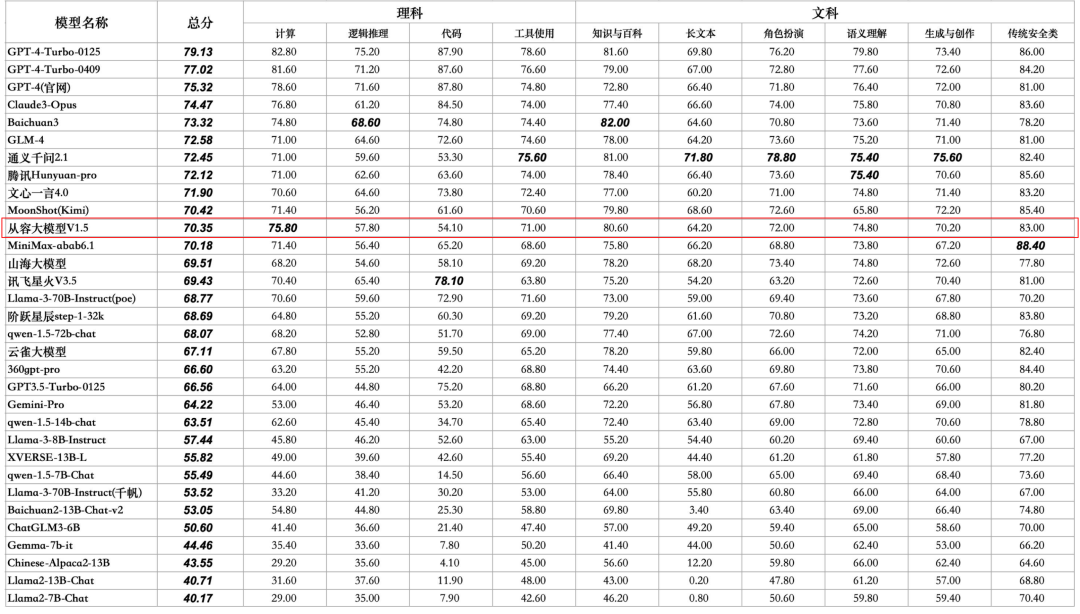
据权威测评机构SuperCLUE发布的最新《中文大模型基准测评报告》,云从科技自主研发的从容大模型不仅成功晋升至【领导者象限】,更以总分70.35分的优异成绩稳居国内大模型综合测评第六位,正式步入国内大模型第一梯队。

本次测评涵盖了32个国内外知名的大模型,从容大模型在激烈的竞争中脱颖而出,显示了其在中文大模型领域的领先地位。特别是与备受推崇的GPT系列模型相比,从容大模型不仅超越了GPT3.5,与全球领先的GPT-4之间的差距也仅为4.97分,标志着云从科技在大模型领域正逐步接近国际领先水平。
综合能力展示
计算能力:从容大模型在计算能力方面以75.8分的高分位居国内首位,展现了其在处理复杂数理运算方面的强大实力。
知识百科能力:在知识百科能力上取得80.6分,排名国内第三,体现了从容大模型在广泛知识领域内的深厚积累与高效应用能力。
语义理解能力:74.8分的成绩证明了其在理解复杂语言结构与上下文含义方面的能力,排名国内前五。
从容大模型在与全球顶级模型GPT-4的直接对决中,取得了20.79%的对战胜率,这一成绩仅次于Claude3-Opus,进一步验证了其在实际应用中的竞争力。这是对云从科技研发团队不懈努力的认可,也是中国AI技术实力的有力证明。

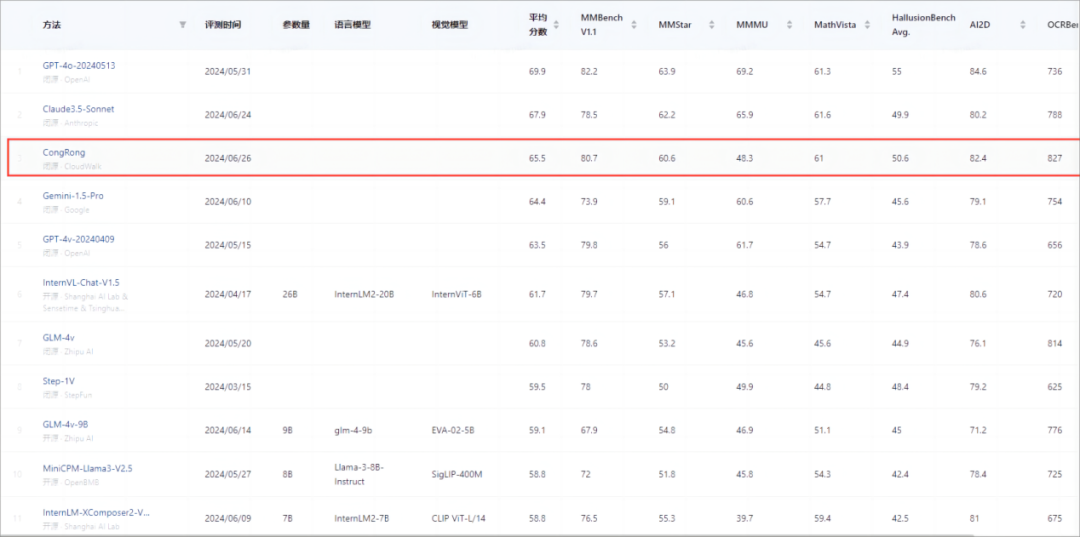
云从科技在综合评测权威平台OpenCompass的多模态评测领域中也取得了重大进展。最新评测结果显示,从容大模型在该体系中的平均得分为65.5,这一成绩使其跻身全球前三,超越了谷歌的Gemini-1.5-Pro和GPT-4v,仅次于GPT-4o(69.9)和Claude3.5-Sonnet(67.9)。在国内市场,从容大模型的成绩也超过了InternVL-Chat(61.7)和GLM-4V(60.8),位列榜首。
此外,云从科技在多媒体领域唯一CCFA类顶级国际人工智能学术会议ACMMM上提出了视觉-语言跟踪大一统模型All-in-One,并在跨模态领域刷新了4项世界纪录。视觉大模型在benchmark COCO上从微软研究院(MSR)、上海人工智能实验室、智源人工智能研究院等多家知名企业与研究机构中脱颖而出,刷新了世界纪录。多模态大模型在ICCV2023细粒度行为检测挑战赛中战胜了早稻田大学、软银等国内外多家知名企业、科研机构,获得了冠军。
云从科技最大的亮点在于,通过自研的多模态大模型基础架构“all in one Transformer”,从容大模型仅需百分之一的算力即可实现媲美第一梯队的AI性能,更有利于降本增效,进一步推动行业大模型和AI智能体的推广和应用。
此次在SuperCLUE的综合基准测评中所取得的成就,不仅标志着中国在AI大模型研发上的显著进步,也预示着云从科技在全球AI竞争版图中正占据越来越重要的位置。