随着AI技术的飞速发展,大模型在众多领域得到了广泛应用。然而在服务过程中,大模型可能因为各种原因输出有害和不可靠信息:常见的例子是,如果大模型未与社会主义核心价值观对齐,则可能在输出内容时违背伦理道德,产生有害信息;另一方面,当大模型受到不当诱导或攻击时,也容易输出偏见歧视、违反商业道德、侵害他人合法权益、违法违规等有害内容。此外,大模型还可能因自身局限性出现“幻觉”,生成看似合理但实际不可靠的信息。


图1:网易易盾安全大模型评测证书及报告首页图
面对上述问题,目前大多数企业的解决方案是在大模型外添加一层审核机制,对大模型服务的输入和输出内容进行安全审核,大模型安全审核服务的能力直接关乎大模型服务的安全性和可靠性。基于此,中国信息通信研究院启动了2025年第一批可信AI(安全)-大模型安全风险防范能力评估工作。杭州网易质云科技有限公司(以下简称“网易易盾”)的“商和大模型-V1.0”顺利通过「大模型安全风险防范能力 第3部分:内容安全的评估」,获评优秀防护级(最高级),成为数字内容风控行业里首位通过该评测的服务商,彰显了行业领先地位与硬核实力!
一、大模型安全风险防范能力系列评估标准介绍
大模型技术正以前所未有的速度重塑着各行各业的生产力格局,2025年多款高性能大模型先后推出,其生成能力和交互能力显著提升,并衍生出多种新的应用方式。随着大模型在各领域的持续落地,其风险问题也日益凸显,如模型窃取、数据隐私泄露、不当内容生成等,包括来自攻击者的对抗攻击、提示泄露、多轮诱导攻击等,时刻考验着大模型的安全能力。
基于此,中国信息通信研究院(以下简称“中国信通院”)人工智能研究所依托中国人工智能产业发展联盟(AIIA)安全治理委员会,联合业界开展《大模型安全风险防范能力要求及评估方法》标准的研制和发布工作,从“训练数据安全、模型安全、内容安全、服务运营安全”几个方面形成大模型安全风险防范能力要求和评估方法,依据标准启动大模型安全防范能力评估工作,进而遴选出一批优秀的大模型服务案例,帮助大模型使用方、应用方等甲方开展能力测试与产品选型,持续推动大模型技术健康有序发展,提升大模型应用安全水平。
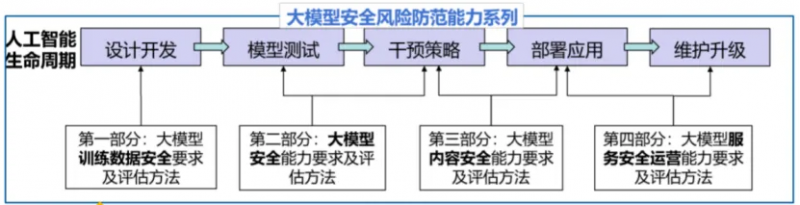
图2:大模型安全风险防范能力系列标准框架
具体来看:
1. 大模型训练数据安全评估
依据AIIA/PG 0151-2024《大模型安全风险防范能力 第1部分:训练数据安全要求及评估方法》,针对大模型技术提供方,从数据生存周期安全和通用数据安全两个过程域,将数据安全能力量化为安全合规要求、技术保障手段和质量控制措施三个方面,帮助其掌握训练数据总体安全情况,发现潜在安全风险。
2. 大模型模型安全能力评估
依据AIIA/PG 0152-2024《大模型安全风险防范能力 第2部分:模型安全要求及评估方法》,针对大模型技术提供方,从模型可信和模型安全两个维度,重点评估其面对干扰的鲁棒性、披露信息的透明度以及输出内容的公平性,以及通过已知模型攻击方法开展模型安全测试,并基于提供方披露信息评估模型的安全保障能力。
3. 大模型内容安全能力评估
依据AIIA/PG 0153-2024《大模型安全风险防范能力 第3部分:内容安全能力要求及评估方法》,面向大语言模型的技术提供者、服务提供者,在模型及服务的内容安全防护过程中,配备的对输入输出内容的识别和过滤能力进行评价。在评估过程中,根据当前大模型服务中常见的意识形态、价值观、涉黄、暴恐、违法、偏见歧视、科技伦理等20余个类型的内容安全风险,按照危害程度划分等级;从模型的预期响应角度,划分为“应该正确回答”、“应该拒绝回答”、“可以正向引导”、“可以按实际能力回答”4个类型。在评估过程中,将选取一定量的数据集,对模型的输出做出验证,根据各风险类型的输出结果给出安全防护能力分级。
4. 大模型服务安全运营能力评估
依据AIIA/PG 0154-2024《大模型安全风险防范能力 第4部分:服务安全运营能力要求及评估方法》,面向通过可编程接口形式为我国境内公众提供大模型服务的组织。在大模型服务部署应用和运行维护阶段,针对数据安全能力、内容安全能力、服务规范要求、运行监测等四个方面评估大模型服务的安全运营能力。
二、网易易盾安全大模型:内生安全+围栏防护 双防御
网易易盾是网易数智旗下一站式数字内容风控品牌,依托网易二十余年的先进技术沉淀和一线实践经验,为开展数字化业务的客户提供专业可靠的安全服务,涵盖内容安全、业务安全、应用安全、安全专家服务四大领域。针对AIGC安全场景,网易易盾通过打造业内首个“内生安全+围栏防护”双维防御体系,让安全能力深度融入“AI血液”,让内容安全战场从单一内容过滤,升级为全生命周期攻防战。
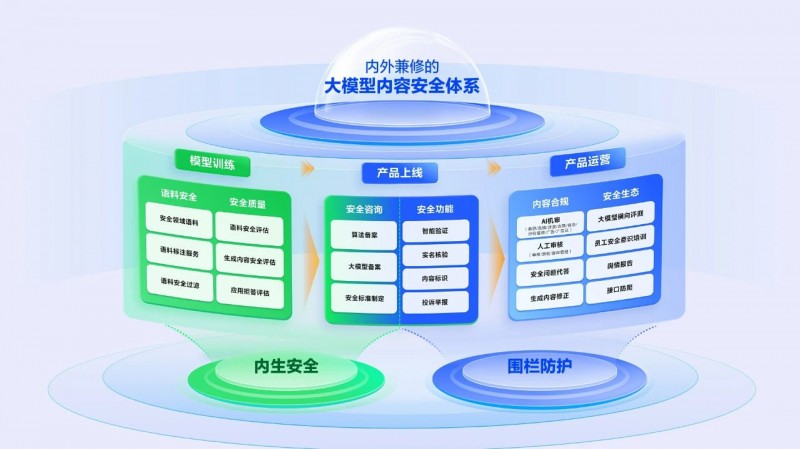
图3:网易易盾大模型内容安全体系建设
内生安全,让安全长于AI基因
从模型训练入手,对语料进行安全领域语料处理,杜绝暴力、偏见等“毒性知识”注入;
加固安全质量,通过对抗样本攻击训练,提升模型抗诱导能力,阻断“越狱”指令;
生成内容修正:实时矫正模型输出中的事实错误、价值观偏差,守好内容合规红线。
围栏防护,给AI应用穿上铠甲
贯穿产品上线与运营全程,产品上线时提供安全咨询与功能服务,如算法备案、智能验证、大模型备案、实名核验、安全标准制定、内容标识、投诉举报等;
产品运营时确保内容合规,开展大模型横向评测、人工审核、安全问题代答等工作。同时构建安全生态,进行员工安全意识培训、舆情报告与接口防爬,二者结合全方位保障大模型内容安全。
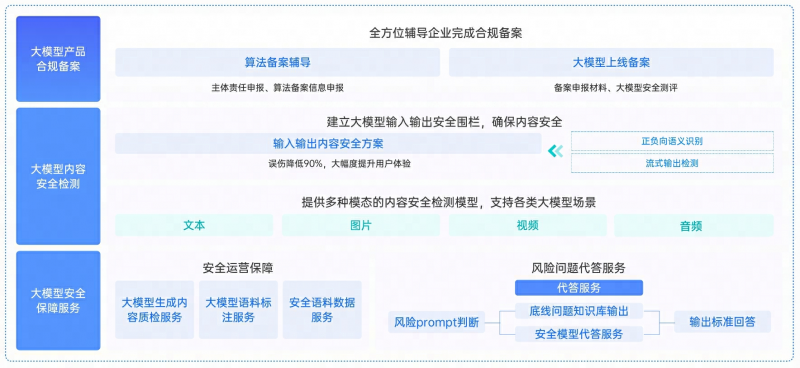
图4:网易易盾大模型内容安全方案架构
网易易盾提供包含语料安全、模型质量、合规功能开发、算法模型备案、内容安全检测、内容价值观检测六大安全治理服务,拥有千万级对AIGC代答知识库,可利用大小模型融合检测技术,根据时政规则实现“应答尽答”。网易易盾成功为100+ AIGC客户服务,获得“硬核”实力认可。
三、为什么是网易易盾
易盾作为首位通过该评测的数字内容风控服务商,绝非运气偶然,靠的是网易二十余年的先进技术沉淀和一线实践经验。网易易盾成立近九年,依托人工智能安全研究,积累了大量产品实践经验,包括行业标准等顶层设计。
近日,国家市场监督管理总局、国家标准化管理委员会发布2025年第10号《中华人民共和国国家标准公告》,由全国网络安全标准化技术委员会(简称“TC260”)归口的6项国家标准正式发布。其中,由网易易盾深度参与的人工智能安全领域重要国家标准:GB/T 45654-2025《网络安全技术 生成式人工智能服务安全基本要求》正式对外发布,并将于2025年11月1日正式实施。


图5:国标 GB/T 45654-2025《网络安全技术 生成式人工智能服务安全基本要求》
该标准适用于生成式AI服务(如大模型、对话机器人等)的安全管理,通过数据安全、模型安全、运营规范三大维度,为服务提供者、监管及评估机构提供技术规范与参考:
数据安全
训练数据需合法合规,禁止采集含5%以上违法不良信息的数据源;
加强多来源数据搭配,跨境数据需境内外合理配比;
严格保护知识产权与个人信息,需用户授权或符合法定情形。
模型安全
训练时需防范后门攻击,定期审计漏洞;
生成内容合格率须≥90%,拒绝回答违法诱导性问题;
重要场景(如医疗、金融)需额外安全措施。
运营规范
提供未成年人防沉迷和内容过滤机制;
需公开服务局限性、数据用途及模型概要信息;
户可便捷关闭数据收集功能(4次点击内)。
该项标准是我国首项生成式AI安全国标,为行业划定了数据、模型、伦理等安全基线,具有风险防控及行业创新等方面的重要意义。作为深度参与该项国标编制的网易易盾来说,“独行虽快,众行方远”,在AI安全的征程上,易盾期待与所有关注AI与安全的伙伴们并肩同行,为AI时代扎紧防护网,让创新始终秉持敬畏之心。