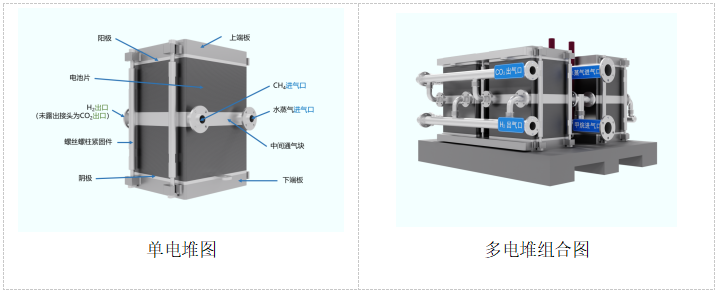
随着互联网和物联网的逐渐普及,各行业都开始源源不断产生单源或多源数据,这些高并发的数据具有高度的实时性和明显的时间序列,数据越热的时候处理,获得的业务价值越高。
随着数字化转型的深入,企业都在积极建设数据能力,开发数据应用,以实现数据驱动业务。邦盛科技是一家专注于大数据实时智能领域的人工智能厂商,提出“时序中间态”技术体系,针对高并发的热数据可毫秒间完成计算。
其核心技术之一是能够实时快速、高并发处理数据的流立方技术,这项技术已成为当前实时处理领域的基础设施平台,可在海量数据规模、分析延时短、复杂事件或复杂指标、智能化决策及时序数据等典型特征的行业场景中,实现实时感知、识别和智能决策,帮助企业更好地实现精准预测、瞬时决策、降低业务成本、提高服务质效。
为了进一步完善公司的实时智能决策与分析体系,邦盛科技历经三年研发,推出时序批计算技术产品“算立方”,补上了邦盛实时智能技术体系的关键拼图,是实时智能从“热数据处理”走到“热知识应用”的关键基础设施。
为了探讨算立方的技术优势和应用场景价值,以及实时智能技术的应用趋势,爱分析近期专访了邦盛科技CTO王新根博士。
王新根博士,现任职邦盛科技CTO,分布式系统性能工程专家,邦盛科技“流立方”、“算立方”平台设计者与研发团队负责人,是实时计算、大数据实时分析技术、大数据流批一体技术等方向的专家,国内“性能工程”博士学位获得者。
01
算立方补上邦盛科技实时智能技术体系的关键拼图
爱分析:请您完整介绍一下邦盛科技的实时智能决策与分析体系。
王新根博士:邦盛科技的实时智能决策与分析技术体系,整体是以流批一体为核心载体,以知识为媒介,糅合流处理、批处理、智能决策等多种技术体系的技术架构。这一架构可以从横向与纵向两个维度来理解。
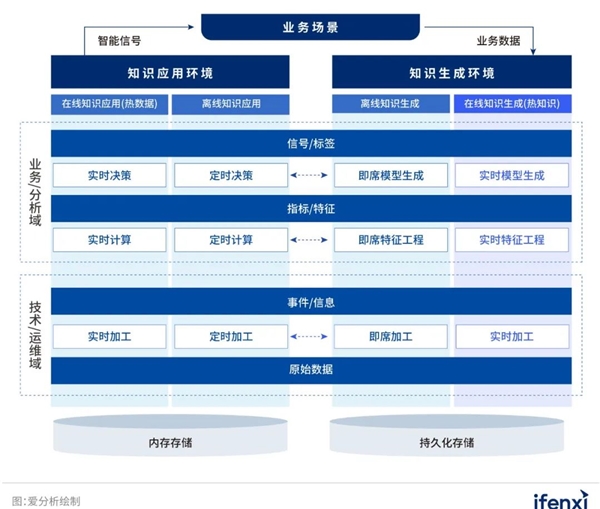
在横向上,实时智能决策与分析体系被划分为知识应用和知识生成两大主要环境,每个环境进一步细分为在线和离线两种场景。
在知识应用环境中,在线场景专注于接近实时的操作,如事务处理中的即时分析和决策,而离线场景则涉及批处理操作,例如银行的T+1数据同步。在知识生成环境中,离线场景的发展已经趋近成熟,而在线知识生成则代表着未来技术的发展方向,特别是在“热数据”向“热知识”领域的渐进探索。
纵向上,技术体系被细分为四个层级,覆盖从数据到决策的整个流程,包括原始数据收集,经过数据加工得到事件事实,再通过计算得到指标特征,最终通过决策生成信号标签。最底层从原始数据开始,构成所有分析的基础。
第二层是从原始数据提炼的事件事实,涉及数据的初步聚合和处理。第三层从这些事件事实中提取维度信息、时间窗口和聚合算子,通过加工计算,形成关键的指标和特征。最顶层则是生成业务所需的信号和标签,如风险控制信号等。
爱分析:邦盛科技新推出的“算立方”,在该技术体系中的定位是怎样的?
王新根博士:算立方主要定位在指标/特征离线计算这一层。实时智能技术体系中,我们在知识应用模块已经取得了很大的成绩,特别是在线知识应用部分,数据实时加工用PipeACE技术解决,指标实时计算用流立方、图立方解决,决策部分自研了独立的智能决策引擎。
离线知识应用部分,在算立方出现之前,我们很早就解决了流批一体的数据定时加工和定时决策引擎,唯独缺失了定时计算这一层,还需要一个跟流立方相呼应的离线计算框架。流批一体融合计算面临着诸多技术难题。流计算和批计算之间存在显著的差异,包括计算方式、支撑模块、资源调度策略以及流程规划等。
因此,要实现有效的流批一体融合计算,需要重点关注数据源的统一、开发的统一、计算的统一、存储的统一,实现技术栈的收敛,减少开发和运维成本,消除不同计算模式带来的逻辑不一致性。
早期邦盛科技采用现有批式技术,但由于计算理念和数据结构的差异,在与流立方、图立方联动方面性能跟不上。在工程突破的时候,我们遇到了巨大困难,决定花大力气把这个短板补上。
经过三年研究和迭代,我们推出了时序批计算产品“算立方”。作为和流立方相配合的批式计算框架,算立方解决了超高性能的定时批式计算效率,实现了有效的面向业务的流批一体融合计算。算立方与流立方相互呼应,分别在离线计算和实时计算方面进行优化配合,降低了流批结合模式的开发和运维成本,使这套技术体系具备独一无二的竞争优势。
爱分析:“算立方”与“流立方”在计算理念和数据结构上是内在一致的,这种一致性如何理解?
王新根博士:整个学术界和产业界的共识是时序数据逐渐成为数据处理的主流形态,我们把“时序计算”提升到非常重要的程度,我们一开始想借助开源去解决问题,但发现和我们的处理理念格格不入。
于是,我们从流立方萃取出了“中间态计算”理念,并把时序聚合的中间态应用到批处理,有了算立方产品。流立方对应“时序流处理”,“算立方”对应“时序批处理”,两者理论指引是完全一致的,数据结构是完全一致的,处理思路也是完全一致的,是一脉相承的。
“时序批处理”技术有其独特的应用场景和价值。例如,在金融场景下,批处理可以用于计算账户当前余额、计算当日累计交易金额、计算到目前为止做了多少次交易等场景。在这些场景下,一般的批处理对时间窗口的含义考虑得较少。
比如,今天一共交易5笔,Spark擅长一次性计算当天整体累计交易金额。但在“时序计算”领域,时间窗口是一项独立的非常重要的能力。当计算如“当日每笔交易后,交易总金额如何变化”这类问题时,用Spark做批处理需要用over函数,且处理起来十分繁琐,每次都需要对原始数据表进行聚合。
而算立方能够实时计算出每一笔交易后账户余额如何变化,即通过对逐笔交易进行计算,实现批计算中间结果的使用。“时序批处理”技术既能够实现逐笔指标的结果显示,也能够实现聚合指标的结果显示,比如按照卡号进行中间结果的聚合。
爱分析:是否可以理解为时序批处理是把数据在时间维度上切得更细?
王新根博士:有一点接近这个理念,Spark通过Spark Streaming给出了自己的解决方案,从批处理到“微批处理”。但我们的时序批处理不仅把时间维度切得更细,而是要切得足够细,细到毫秒级,这是Spark最欠缺的一块能力。比如1秒内发生了10笔交易,其中的第一笔交易不能考虑其他9笔交易的情况,否则整个时序批计算的准确性就有问题。
爱分析:算立方的数据模型是立方体Cube,这与类似Kylin的Cube这种多维数据模型有什么区别?
王新根博士:算立方产品的Cube架构具有三个关键维度。
第一,数据维度,这与Kylin相同。该维度涉及到各种类型的数据元素,例如IP地址、手机号码、设备标识、银行卡号等,这些元素构成了数据处理和分析的基础。
第二,指标维度。例如,对于一张银行卡,可能需要计算的指标包括累计交易金额、账户余额等。这些指标为数据分析提供了具体的分析角度和计量标准。
第三,时间维度。这是邦盛科技算立方独特的第三维,即专注于时间序列的处理。在进行计算时,可以根据需求将数据切分成不同的时间段,并形成聚合数据。例如,如果需要计算过去6小时的数据之和,Cube可以将这6小时切分成每小时一段的6小段,然后对每个小时段的数据进行聚合计算。
算立方中,Cube通过使用聚合算子提前进行聚合计算,生成了“时序聚合中间态”。在上述例子中,每小时的计算数据都会形成一个“时序聚合中间态”。这个中间态需要通过三个维度来定义:用户、指标和时间。如果需要计算平均值,那么这个“时序聚合中间态”会存储结果和数据个数等变量。类似的聚合算子邦盛科技已经开发了30多个,进一步增强了算立方的数据处理能力。
02
三年磨一剑,算立方大幅提高时序批计算效率
爱分析:请展开介绍一下邦盛科技自研算立方的历程?
王新根博士:如之前提到的,我们之前的技术体系中批计算主要依赖Spark,然而在与竞争对手的比较中,发现仅依赖Spark在性能上并无明显优势。面对这一挑战,我们采取了多项措施。
首先对Spark的over时间窗口函数进行了调整,以增强其对热点数据的处理能力。尽管如此,这些改进的效果仍然有限。我们还尝试将流立方的算子嵌入Spark体系中,但最终发现Spark在性能方面仍无法满足公司的需求,这种方法不能从根本上解决问题。
因此,邦盛科技决定从头开始研发“时序批处理”技术,即算立方。在算立方的研发过程中,我们也注意到金融行业客户对架构控制的严格要求,多数金融客户不允许在其大数据环境中部署一套完全独立的计算系统,而是需要满足Spark HDFS的架构。
因此,算立方也按照这一要求进行了研发。从2018年开始,公司投入了三年时间来研发算立方。到2022年,算立方在某股份银行的反洗钱应用中进行了实践,其效果获得了银行的全面认可。这一成功案例不仅证明了算立方技术的有效性和成熟度,也展示了邦盛科技在时序计算处理能力方面的创新和技术实力。
爱分析:算立方与Spark相比,体现在性能指标上的优势如何?
王新根博士:Spark非常擅长通用的批处理能力,包括说数据的join、排序、面向通用场景的聚合计算等等。算立方主要是为了补足时序批处理的能力,两者不是互斥的,而是互补的关系。
中国信息通信研究院对算立方与Spark在时序批计算领域的性能进行了详细的评测。在这项评测中,两种计算方式在相同的任务环境下(包括相同的硬件、计算逻辑和数据量)进行了对比。测试结果显示,在少量指标的计算任务中,算立方的性能超过Spark 55倍。更值得注意的是,随着指标数量的增加,算立方的性能优势还会进一步扩大,可以超过Spark 100倍。
爱分析:算立方在性能上有这么大的优势,背后的技术原理是怎样的?
王新根博士:这一显著的性能差异主要归因于算立方与Spark在计算逻辑上的不同。Spark在进行计算时,每个指标都需要开发一个对应的SQL语句。在需要同时计算多个指标的批处理场景中,Spark要求每个语句都通过不同的计算单元分别进行运算。
这种方法的缺点在于,如果每个计算单元都需要加载同一张表,那么该表就需要被多次加载,降低了效率。而算立方在处理时遵循“at most once read”的原则。
具体来说,算立方首先会一次性读取涉及到的所有表格,然后一次性处理所有相关指标,确保每张表最多只被读取处理一次。在对所有数据进行时序排序后,每条数据源也只会被处理一次。最后,这些数据将形成一个指标宽表。
因此,随着指标数量的增加,算立方相比于Spark的性能提升更加显著。在实际应用场景中,算立方的“增量批处理逻辑”也显著提高了计算效率。例如,每天需要计算前30天的数据之和时,Spark每天都需读取前30天的数据并计算,而算立方能够在新一轮计算开始时直接调用前29天的计算结果,并仅添加新一天的数据进行计算。
此外,Spark在处理热点数据造成的数据倾斜问题时性能较弱。例如,如果某个客户占据了大部分交易流水,Spark的计算资源消耗上会非常高。而算立方得益于其对聚合算子的乱序计算能力,能够更高效地进行并行计算。
算立方在处理分区计算的均匀性、协调性和数据倾斜优化方面表现出色,加之“at most once read”的原则,保证了内存使用更少,计算过程更稳定。在流批一体的场景下,流立方与算立方内置的30多种算子能够无缝衔接,使流批一体计算变得更加自然和流畅。这种高效的计算逻辑和优化策略使得算立方在时序批计算领域表现出色。
爱分析:上述提到了算立方需要满足Spark HDFS的架构,那么算立方与Spark生态的关系是什么?
王新根博士:在开发初期,考虑到Spark在批计算领域几乎形成了垄断地位,算立方也希望能够依托该生态体系进行应用。于是,算立方被定义为类似 Spark中的GraphX的计算框架,插入到Spark生态系统中,而非替代它。这种设计理念体现了算立方与Spark之间的互补性,而非竞争关系。
爱分析:算立方对邦盛科技整个实时智能技术体系的竞争优势有什么增强?
王新根博士:首先,流批一体计算体系的部署时间得到了显著缩短。在引入算立方之前,使用Spark进行规则实施时,比如需要判断用户过去180天的行为,Spark需要花费数天时间来补全时间窗口。这一长时间的等待对于实时决策和快速响应的需求构成了严重制约。
引入算立方后,得益于其显著的性能提升,相同的任务部署时间可以缩减至小时级。这种时间上的优化极大地提升了业务的灵活性和响应速度,对于需要快速迭代和更新规则的环境尤为重要。其次,算立方在机器学习建模场景有很大潜力。
在算立方和流立方的体系中,机器学习建模的效率得到了显著提升。以往的特征工程需要建模工程师使用Spark或Hive编写代码,且迁移到实时应用场景可能需要高达两个月的时间来完成指标的开发、测试和投产上线。
算立方改变了这一状况。由于算立方提供了面向建模工程师的专用SQL,并且该SQL语句可以被流立方理解,这使得建模工程师能够实现一键式的模型迁移和上线。这种能力不仅简化了建模过程,还加速了从模型开发到实际应用的转化,为快速部署和实时数据分析提供了有效支持。
03
实时智能技术正在反诈等场景充分发挥效能
爱分析:基于流立方、算立方等产品,邦盛科技服务了哪些行业客户?销售模式是怎样的?
王新根博士:邦盛科技在金融行业拥有丰富的客户基础。金融行业对前沿科技应用较多,这一特点使得邦盛科技能够根据客户需求进行快速的产品迭代。金融行业通常需要处理大量复杂的数据,并且对数据处理的速度和准确性有极高的要求,邦盛科技的流立方和算立方等产品在这一领域尤为适用。
除了金融行业,邦盛科技的业务也涉及到其他领域,包括通信、交通、政务、网络安全和国防等。在这些行业中,邦盛科技还在寻求与行业专家和头部企业的合作,以开拓新的产品应用场景。例如,公司与浙江移动的合作就是在通信行业中应用技术的一种尝试。
在销售模式方面,邦盛科技主要采用直销策略。公司将直接与客户接触,理解其具体需求,并提供定制化的解决方案。在这些解决方案中,流立方或算立方可以作为关键组件之一,根据不同行业和客户的具体需求进行部署和调整。
爱分析:邦盛的实时智能决策与分析体系现阶段主要在哪些行业场景有落地应用?
王新根博士:邦盛科技的实时智能决策与分析技术体系,在不同行业具备广泛适用性。在从IT(信息技术)到DT(数据技术)的转变中,大数据的有效应用成为主要趋势,但当前实时智能的应用正处于起步阶段。实时智能决策与分析在结构化数据领域成为关键基础设施,尤其在涉及高对抗性的领域,其重要性更是不言而喻。爱
分析:您能否介绍两个典型的应用案例?
王新根博士:首先是金融行业的案例。在反洗钱方面,算立方相较于传统的Spark计算,能够更加精准地识别洗钱行为。一般的洗钱模式是欺诈者首先对银行卡进行小额测试,之后把该张卡当成洗钱通道,大笔金额开始快进快出,最后在当日结束时,将卡内金额全部转出。
在使用Spark进行批处理时,识别洗钱风险需要满足三个条件:
1)该账户当日进行小额测试;
2)接下来大金额的快进快出;
3)日终小余额。
三个条件全部满足,则判断该张卡片可能涉嫌洗钱。但是现阶段,欺诈者会在日终再转一笔金额入卡,导致使用Spark处理时无法识别出风险。而算立方能够通过对当天整体交易轨迹的分析,判定是否存在风险。在上述场景中,可以在发生第一笔大额转出交易时就警示风险,即更早、更准确地警示风险。这种方法在某股份制银行的应用中,能够比传统系统多识别出40%的风险交易。
再举一个通信行业的例子。在与浙江移动的合作中,邦盛科技的技术被应用于反电信诈骗,特别是在DPI(深度数据包检查)领域。DPI技术使网络所有者可以实时分析通过网络的流量,了解用户的性能或行为,并进行服务改善。
在邦盛科技与浙江移动合作的案例中,浙江移动将大多数地级市的流量接入,通过分析上网行为,进行反电信诈骗分析。例如定位访问涉赌涉诈网站的使用者,对他们进行行为统计,并在某些特点行为发生时进行干预。比如访问涉诈网站后,又访问金融APP,此时,流立方能够经过计算迅速给出高紧急信号,并将信号直接发送公安部门,公安部门能够马上打电话拦截交易。
在该案例中,流立方处理的网络流量级能够达到每天600亿接入量,使用后期因为应用效果较好,现阶段已经开始全盘接入浙江省3000亿的流量。现在该项目进入第二阶段,将接入算立方,主要应用方向为鉴别黑灰产网站。由于这些涉诈网站经常只存在一天,导致监管很难及时发现并进行干预,算立方接入后,将探索使用即席特征工程,加入新的规则模型,计算出这类网站的特征,提前进行拦截,流立方与算立方联动变得越来越快,使监管能够处于防控的第一线。
爱分析:除了反洗钱、反诈这种高对抗场景,算立方及实时智能技术在企业的营销、运营等业务场景是否有相关应用?
王新根博士:邦盛科技正在探索算立方在营销方面的应用场景,特别是营销案例结果的计算与运营。例如一个为期一天的营销案例中,需要从几千万客户中选出5000个进行精准营销,购买理财产品。该理财产品采用实时竞价购买,买的最多的前十位客户,将在当天晚上5点结算并寄送礼物。在这个过程中,营销活动的客户圈选,竞价计算,机器人私有域的联动,到最后将礼物邮寄出,都能通过算立方完成数据分析。
04
从“热数据”到“热知识”,实时知识生成释放数据价值
爱分析:甲方企业在做批计算引擎的技术选型时,主要的考量因素有哪些?算立方有哪些迭代方向?
王新根博士:甲方企业在技术选型时,主要以性能为导向。批计算领域,计算速度快不仅意味着算力的节省,还能够满足业务敏捷变化的需求,高效的计算能力能够确保业务在第二天上班前就能获取所需的数据。
在算立方产品上,其核心技术已经实现突破,未来主要进行落地应用的推广探索。未来,算立方的工作重点涉及页面的友好性与易用性,打造使用友好的UI界面,并对运行过程中的监控、 异常的恢复、对于中间某历史数据变化的修复能力等进行拓展。
爱分析:邦盛科技未来在实时智能技术体系上有什么样的规划?
王新根博士:邦盛科技的实时智能战略在未来5年都不会变。在未来3-5年,邦盛科技将聚焦于“热知识”的细分领域探索。现阶段主流的知识生成都是使用离线计算,未来将向“热知识”领域探索,即数据实时抵达,实时挖掘数据价值,实时产生规则模型,实时应用到正在新发生的数据里面,将知识的部署使用从月级提升到天级、小时级。现阶段技术上仍需一定程度的提升,例如数据的实时增量处理,实时增量即席特征工程,机器学习算法对整个过程的优化等。
THE END