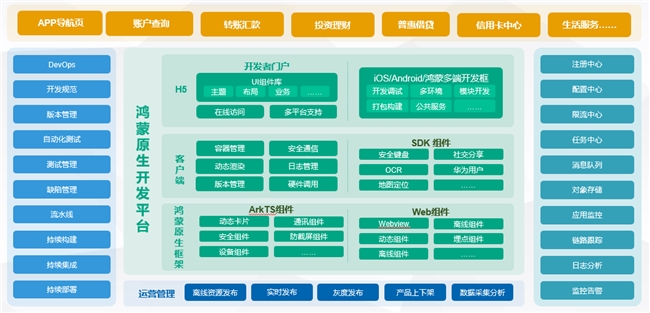
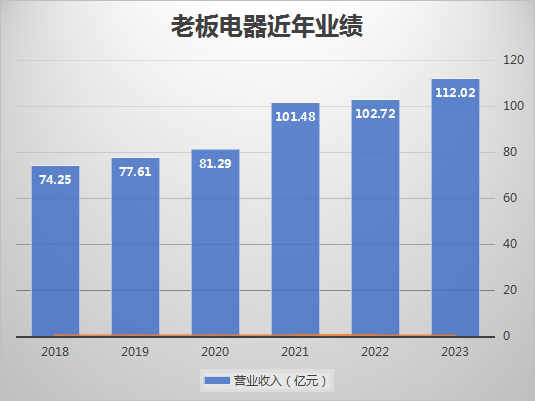
随着AIGC时代的到来,数字人生成技术正逐渐成为焦点。出门问问自主研发的照片数字人引擎,凭借持续的技术创新,让用户仅需一张照片就能快速生成可以说话、讲故事的动态视频。目前,这一引擎已成功应用于国内产品「奇妙元」以及国际产品「DupDub」。
出门问问不断迭代照片数字人引擎
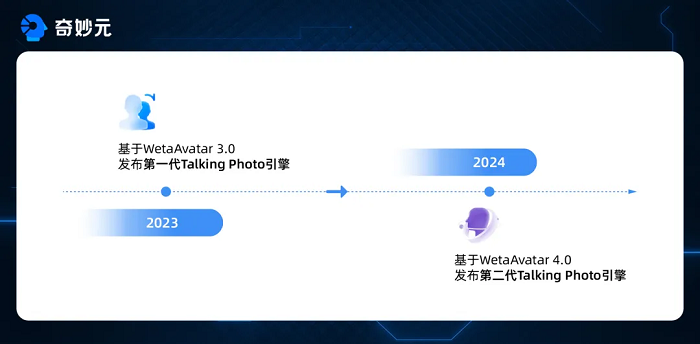
自2023年推出WetaAvatar 3.0数字人系统及其照片数字人引擎以来,出门问问凭借其易用性和生动的生成效果,迅速赢得了用户的青睐,进行了形式丰富的内容创作。为了进一步提升用户体验,我们推出了最新一代的照片数字人引擎——WetaAvatar 4.0-Talking Photo。这一版本不仅优化了视频生成的清晰度和真实感,还显著加快了合成过程。同时,我们也在积极开发照片数字人实时对话引擎,不断推动技术创新的边界。
在新一代照片数字人引擎WetaAvatar 4.0-Talking Photo中,用户可以体验到以下优化:
合成速度翻倍:合成速度显著提升,大幅缩短等待时间。
背景渲染优化:视频背景渲染精准,与原图色彩无缝匹配。
人物背景分离增强:确保人物与背景之间的高度解耦,提升视频质量。
牙齿与嘴型精准复现:细节处理更出色,确保牙齿和嘴型的真实性和自然性。
大模型赋能 自然语音输出
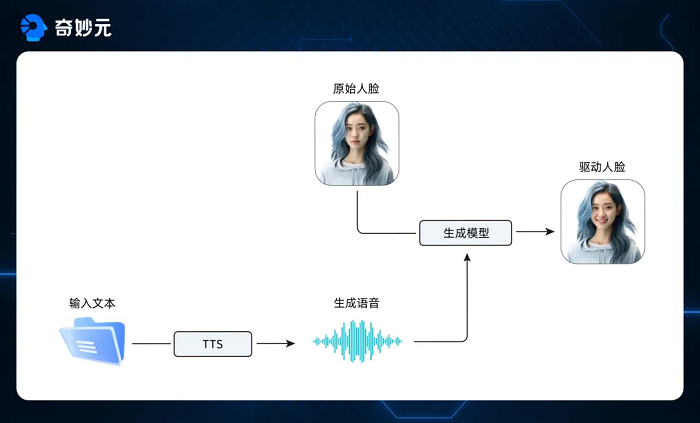
用户仅需提供文本内容,便可借助出门问问的MeetVoice Pro语音大模型,生成自然流畅的语音输出。之后,结合我们的数字人系统,这些语音将被转化为精确同步的嘴形动作和自然的表情变化,创造出动作流畅、表现力丰富的数字人视频,为用户提供一种全新的互动体验和内容创作方式。

两大技术模块 促成高质量效果
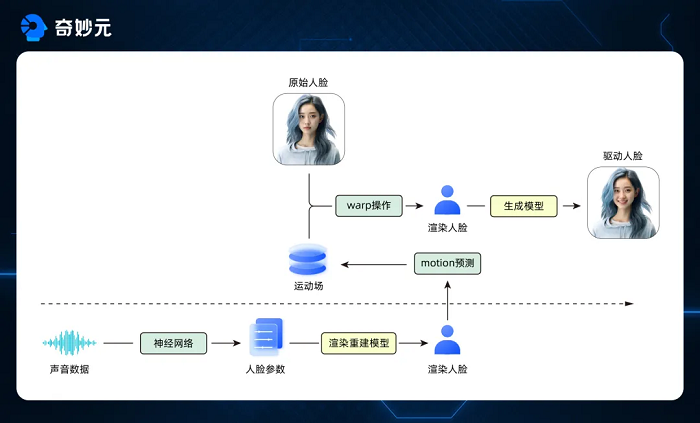
WetaAvatar 4.0-Talking Photo是一个高效的双模块引擎,专为生成逼真的照片数字人视频而设计,包含两个核心组件:运动预测模块和人脸驱动模块。运动预测模块: 此模块利用先进的语音分析技术,从输入的语音中提取关键参数,这些参数随后用于精确生成与之匹配的嘴型动画。这个过程涉及到复杂的算法,能够确保嘴型与语音的节奏和强度完美同步,从而创造出自然流畅的说话效果。人脸驱动模块:此模块则进一步增强了视频的真实感。它结合了预先生成的驱动视频和用户输入的静态图片,通过算法生成一个全面的运动场。这个运动场不仅包含了嘴型变化,还能够模拟出丰富的面部表情和微妙的肌肉运动。随后,这个运动场可以用来驱动输入图片,生成具有高度表现力和动态变化的数字人视频。基于以上两个模块,在新一代Talking Photo引擎中,不论是人物正脸或侧脸驱动,其表现均优于前代,技术指标Sync-C的数值普遍高于WetaAvatar 3.0-Talking Photo引擎。
Sync-C (SyncNet Confidence):使用预训练的衡量音画同步性的模型 SyncNet 计算的音画同步置信度。相同的驱动音频和驱动视频,数值越高越好。
更多创作形式 尽在探索
目前,「奇妙元」平台已经搭载WetaAvatar 4.0-Talking Photo引擎,用户能够释放创意潜力,将风格各异的人物照片驱动,生成高质量的动态视频,实现人物自然地说话、讲述,甚至唱歌的视频效果。
「奇妙元」支持对皮克斯风格照片进行人物驱动,效果与真实人物几乎无异。
如照片中的人物有胡子等面部遮挡物,「奇妙元」依然能够精准捕捉面部特征,保证图像生成的准确性。
对于年代久远的老照片,「奇妙元」能够进行精准上色和高清渲染处理,进而驱动照片中的人物,让这些珍贵的记忆焕发出新的活力。
展望未来
出门问问技术团队致力于推动数字人技术的发展,目前正专注于基于WetaAvatar 4.0-Talking Photo的实时照片对话引擎的研发工作,预计不久将投入使用。我们不仅注重技术的创新,更着眼于提升用户体验,旨在通过生成更真实的表情和丰富的动作,打造出具有高度情感表现力的照片数字人。随着大模型时代的到来,出门问问数字人团队也将持续深入探索基于大模型的数字人生成技术,以Sora模型的问世为里程碑,期待在大模型的加持下,创造出更加生动、真实的数字人,为用户提供更加丰富和深入的交互体验。