随着智能化技术的飞速发展,尤其是以生成式AI为代表的技术快速应用,推动了数据与智能的深化融合,给数据基础设施带来了新的变革和挑战。如何简化日益复杂的系统架构,提高数据处理效率,降低开发运维成本,促进数据开放共享和创新应用,成为企业关注的核心问题。
一站式大数据平台,旨在通过一个平台即可满足各类业务需求,成为数智融合时代下数据基础设施的发展趋势,并从四个维度向四个“一体化”方向演进:数据架构-湖仓集一体化;数据处理-多模型一体化;数据分析-历史与实时数据一体化;资源管理-多集群应用、资源和数据一体化。
数据架构:湖仓集一体化
过去,企业在建设数据平台时通常使用传统的Hadoop湖+MPP仓的混合架构,逐渐有部分企业开始使用类似Hudi/Iceberg的湖仓技术。这两种技术架构都存在一些局限性,在线分析能力较弱,无法满足集市业务需求。因此企业往往需要再引入额外的分析查询引擎,用混合架构来满足湖仓集业务需求。
混合架构中,数据需要存储在不同平台里来提供服务,首先就造成了数据冗余和存储资源占用。其次,数据需要跨平台ETL流转,流转开销高,时效性较差。数据跨平台流转中还容易导致数据一致性问题,影响业务正确性。此外,多平台的开发标准不一致,存在一定的技术门槛,权限管理复杂。
星环科技大数据基础平台TDH从2014年支持了事务表和存储过程开始,形成了湖仓集一体雏形,在2023年TDH9.3版本中引入了湖仓集统一存储格式Holodesk,只需一种存储格式即可同时满足ODS数据实时数据接入、数仓模型加工和高性能集市查询分析等业务,不需要针对不同的业务场景使用不同的存储引擎而构建烟囱式混合架构。在星环一体架构下,湖仓集对用户来说,仅仅是业务逻辑上的区分,底层使用统一的技术栈,真正实现湖仓集一体化。
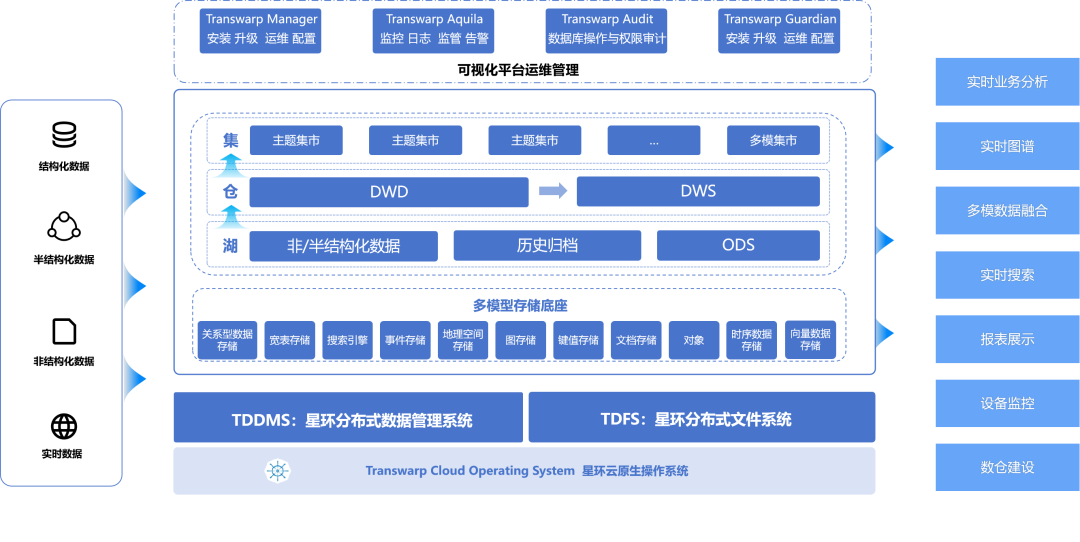
新发布的TDH9.4在资源隔离、端到端性能、统一运维管理等方面升级,帮助用户构建真一体化、高性能、易运维的湖仓集一体化平台。
* 资源隔离新架构,在同一份数据上跑批查询混合负载互不影响。一套集群一份数据,基于Raft协议保障分布式一致性,在CPU、内存、IO、网络资源方面完全隔离,结合基于容器化的动态资源调整能力,保障不同的批量业务与查询业务性能需求。存储方面,针对湖仓集多种混合负载业务,支持分区级多级冷热数据存储,最大化利用存储资源,降低总体存储成本。
* 端到端性能10倍提升,全面降低TCO。相比于Hudi+Clickhouse+Hbase的混合架构,TDH湖仓集同一份数据,ETL时间节约95%,存储空间节省3/4,批量入库性能提升3倍,实时入库性能提升5倍,批量加工和多表关联分析性能提升5-10倍,统计性能提升3倍,带小量聚合的查询业务性能提升1.5倍。
* 湖仓集统一运维管理,大幅降低运维管理成本。湖仓集统一的监控导向UI,提供更细粒度的集群运行、资源使用、组件指标等监测,提供界面化补丁管理、磁盘管理等。此外,TDH支持X86和ARM混合集群部署和统一管理,首个在10000节点X86/ARM混部集群下,通过信通院云原生湖仓一体专项评测。
* 支持 Python 生态,高效支撑大模型应用。基于统一的分布式计算引擎,提供分布式Python引擎,来帮助用户更方便地用Python进行分布式数据处理。并提供POSIX接口,挂载分布式文件系统TDFS到本体磁盘,让用户可以像处理本地数据一样处理海量AI训练数据,高效支撑数智融合时代下大模型应用和各类数据智能场景。
数据处理:多模型一体化
过去,不同的数据模型往往需要独立的平台来处理,而这些不同的产品在接口标准上不一致,开发者和业务分析人员需要掌握不同的语言。同样,这些产品也使用了各自独立的计算引擎和存储,数据存储在各自生态中难以互通,在业务上如果涉及到跨模型的混合业务,需要把数据从一个平台导入到另一个平台中,ETL流转效率低,同时也难以保证数据的准确性、一致性和实效性。
多模数据库旨在单个系统中集成了多个关系型和/或非关系型数据引擎(例如,文档、图、键值、时序等),满足业务对于结构化、半结构化、非结构化数据的统一管理需求,实现数据的多模融合处理。通过使用单个系统来降低操作的复杂性,更好地支持不同场景下的多种类型数据处理。
随着大语言模型的快速发展,对于多种模型数据的处理需求越来越高,同时由于其存在领域知识缺乏、知识时效性低、回答易幻觉、隐私数据不安全等局限性,需要通过检索外置知识库的方式来增强大模型能力。通过多种模型一体化处理的平台,在增强大模型的同时,可以降低系统搭建、开发、运维等方面难度,因此多模数据库成为大模型时代的刚需。
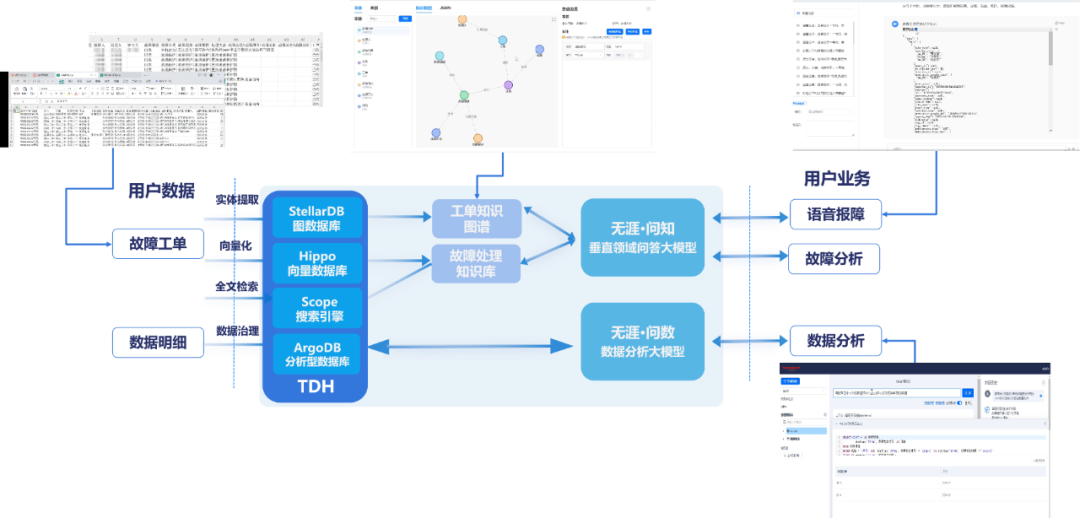
星环科技从2020年实现了多模型数据的统一处理技术,基于四层统一的架构提供统一的接口层,统一的计算引擎层,统一的分布式存储管理层和统一的资源管理层,并支持关系型、图、时序、时空、向量、键值等11种数据模型,业内首个通过了信通院《多模数据库技术要求》评测。

TDH9.4在多模型能力进行了升级,向量存储引擎Hippo发布了2.0版本,单机存储容量提升20倍,结合分布式架构可支持百亿字的向量存储,检索性能提升10倍以上,并提供完整的企业级能力,包括冷热灾备、跨集群数据同步、生命周期管理等,帮助用户更安全、便捷地支撑大模型应用。
图存储引擎StellarDB发布了5.1版本,引入GPU作为计算资源,部份场景下如子图查询性能提升10倍以上,结合深度图算法提供图谱召回、图谱推理等能力,提升大模型的准确度,帮助用户构建企业级知识库系统。
基于TDH多模型统一技术架构,满足大模型场景下多模态数据的统一存储管理与服务,大幅简化知识库的知识存储与服务层架构,降低开发与运维成本。通过将TDH作为大模型外置知识库,可以检索文本/图片/音视频转化后的向量数据、图数据、以及传统关系型数据等,并进行联合召回,可以极大增强大模型的准确率。
数据分析:实时与历史数据一体化
随着业务的快速发展以及企业内部决策的要求不断提高,用户对数据实时性的要求越来越迫切。实时数据处理架构Lambda和Kappa,在各自使用的场景都能解决一部分实时或近实时的用户需求,但是随着业务实时要求的提高,两种架构均存在一定的不足,主要体现在:
(1)Lambda架构将实时和历史数据分离,随着历史数据的积累,批量计算的性能会下降明显;
(2)Kappa架构通过流计算的方式实现了数据融合,但流与流之间的时间窗口难以精确控制,流与流存在数据关联不上的问题。
星环科技ArgoDB 6.1版本中推出了数据增量计算能力,提出了业务实时计算新范式。在实时处理数据架构上,解决了Lambda架构中的实时与历史数据的不融合问题;同时避免了Kappa架构中的流与流计算窗口不可控问题。从数据的加载到数据的加工,保障了数据业务端到端的实时性能,极大地提升了业务分析的时效性。
ArgoDB6.1的增量计算技术,打破流表和物理表的使用壁垒,增量交由数据库识别、关联和分析:
* 大幅降低资源维护成本,窗口下沉到存储,数据无中间状态,流状态时间窗口维护成本从100%降至0(即“零”维护成本);
* 实时性能 & 数据准确性提升,减少计算数据量,为结果表实时提供最新的关联计算值;(即数据“不丢”“不重”且“计算高效”);
* 增量数据可重复使用,原始数据落表,增量的数据可供下游使用,配置链路简单且数据可重复使用。
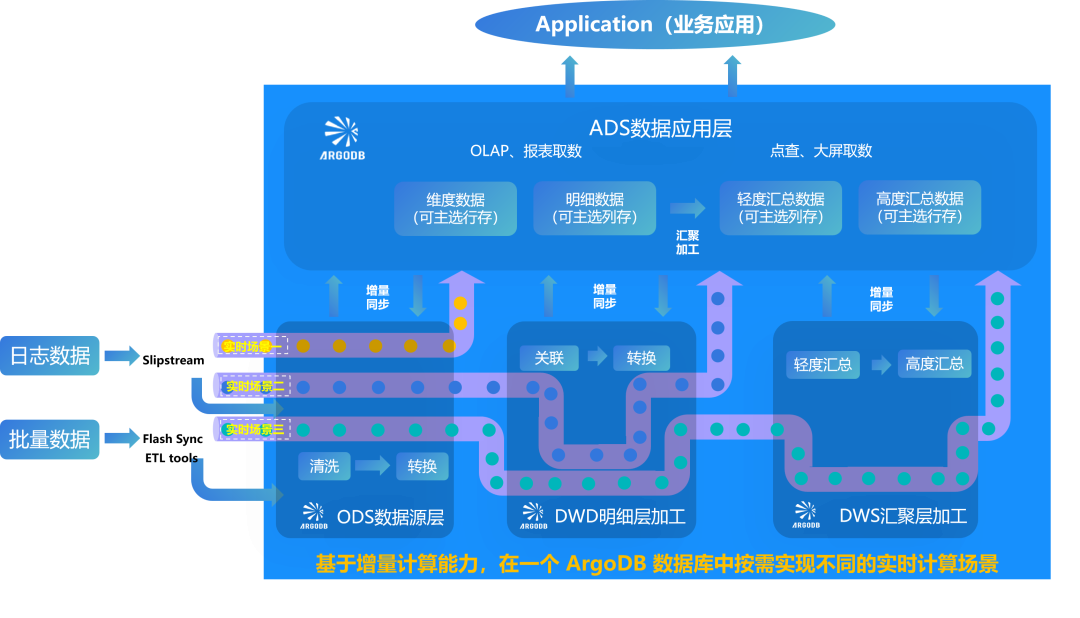
基于ArgoDB 6.1增量数据计算能力,可在一个数据库系统中实现多种实时场景,数据仅需在库内流转:
场景一(即席查询,写入即服务):数据直接写入ArgoDB,由ArgoDB提供OLAP 查询和在线服务;
场景二(增量数据准实时加工):在 ArgoDB 中进行ODS数据清洗,并在DWD数据明细层预加工后直接进行汇聚层加工,对接上层应用;
场景三(增量数据实时统计,事件驱动加工):DWD明细层预加工和DWS汇聚层预加工全部由ArgoDB增量计算完成,并提供给上层应用,帮助用构建新一代的实时数据仓库。
资源管理:多集群应用、资源和数据一体化
企业通常根据不同的业务系统构建多个不同的大数据集群,多个集群的运维管理给企业带来了很多困扰。不同的集群各自孤立,底层资源无法统一、无法均衡的调度和最大化利用,并且各个集群上的数据难以互通,当涉及跨集群数据调用时,需要在各个集群之间ETL,效率较低,也难以保证数据的准确性、一致性和实效性。当有新业务需要上线时,需要建设新的集群,进一步加剧上述问题。
多个大数据集群统一管理,能够将多集群统一纳管,实现资源统一调度,数据统一管理,并能够快速响应,满足新业务上线需求。
星环科技数据云平台TDC,在一个平台上提供了数据PaaS、分析PaaS、应用PaaS服务,底层共享基础设施资源,能够实现不同业务、不同环境下的多个集群统一纳管,不仅提供星环科技的大数据与人工智能产品等产品服务,也能够托管如Spark、Flink等开源生态产品。
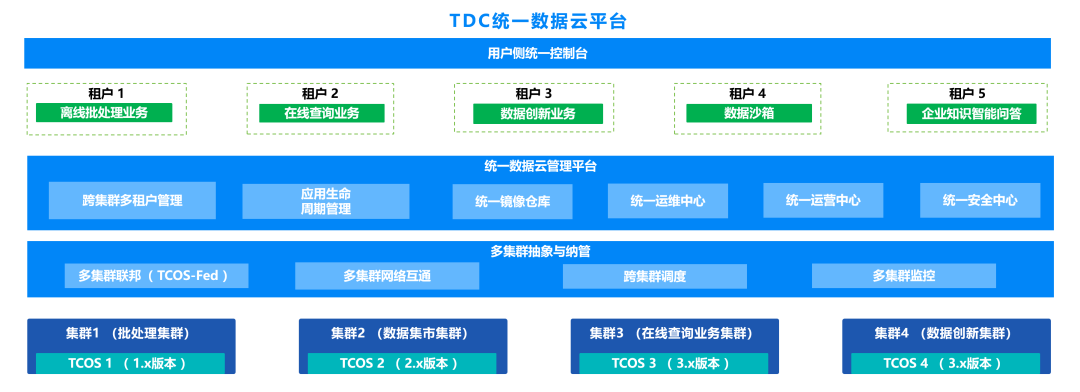
TDC 5.0在多集群及应用统一纳管基础上,对跨集群资源均衡调度、自动弹性伸缩、数据共享等能力进一步升级,帮助用户构建一体化的大数据与智能平台,降低企业多集群运维管理成本,最大化资源利用率,加速业务上线与创新。
跨集群资源均衡调度 实现对多个集群底层资源的统一管理,当某个集群负载较大,需要扩展存储或者计算资源时,能够跨集群自动调用富余集群的资源,实现多个集群之间资源的均衡调度,提升所有集群的整体资源利用率。
跨集群自动弹性伸缩 根据配置的基于时间周期、负载变化的自动弹性伸缩策略,对业务繁忙时间段和业务负载突增时,自动进行存储和计算资源的扩缩容,满足业务对资源的需求,保障业务性能的稳定性。
跨集群数据共享 跨多个集群实现数据的共享,集群之间不需要做ETL,可以直接共享使用对方集群的存储,进而实现No Copy的数据共享,避免数据复制带来的存储压力和数据时延,以及不一致性问题。