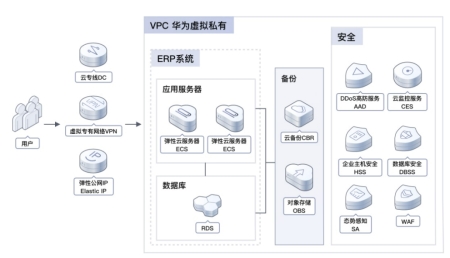
在6月21日举行的华为开发者大会(HDC 2024)上,华为云推出了盘古媒体大模型,通过在语音生成、视频生成和AI翻译三方面的技术创新,重塑了内容生产和应用的新模式。
盘古媒体大模型在视频生成方面取得了显著成果。通过盘古,可以将实拍视频转换为不同风格的高清动漫。在现场演示的生成视频中,演员的舞蹈、武打等大运动轨迹能保持一致视觉效果,角色的面貌特征也保持前后一致。这一技术的突破,为视频制作领域带来了全新的可能性,也大大提升视频制作效率,作品一次拍摄多元化制作,实现价值最大化。
在语音生成方面,盘古大模型通过AI原声译制与视频生成能力,实现了将原片译制成不同语言的视频,并保留原始角色的音色、情感和语气。更为重要的是,盘古还能同步生成新的口型,确保不同语言对应的口型一致,使得跨语言沟通更加自然流畅。
此外,在AI翻译方面,华为云盘古大模型也对云会议系统进行了升级。通过基于大模型的语音复刻、AI文字翻译以及TTS技术,实现了语音的同声传译。这使得不同国家的人在云视频会议中可以畅快地使用母语交流。结合数字人技术,在不方便开摄像头时,用户还可以通过数字人参会,并通过口型驱动实现数字人以各种语言说话都能精准匹配口型,如同本人说话一般。这一技术的应用,将为全球用户提供更加便捷、高效的跨语言沟通体验。华为黄超在现场演示了新的云会议系统。
华为云盘古大模型5.0的推出,将进一步推动媒体内容生产和应用的创新发展,为用户带来更多便利和价值。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。